Java八股文-消息队列学习记录2
4.Kafka的特性
1.消息持久化
2.高吞吐 100万
3.扩展性强(动态),集群
4.多客户端支持(Java,Go,C++)
5.Kafka Stream (流处理) 双十一
6.安全机制
7.数据备份
8.轻量级
9.消息压缩
7.kafka中比较熟悉的参数
broker.id 每一个broker在集群中的唯一表示。
log.dirs 消息保存的路径。Kafka把所有消息都保存在磁盘上。
auto.create.topics.enable 是否允许自动创建主题
11.kafka适合的场景
限时订单不可以。没有对每条消息做限时的发送。RocketMQ可以
日志收集。很适合。并发量比较大。天生持久化,默认写磁盘。
消息系统。作为一款生产-消费的消息系统。
流式处理。Stream的流的组件。 Flink+Kakfa 做一个异步。
13.为什么kafka不支持读写分离
支持主从,但不支持读写分离。主写从读
1.数据一致性问题
2.延时问题。redis是基于内存的,kafka是要写磁盘的
3.实现了主写从读后,实现不了负载均衡
4.不实现读写分离,架构简单,出错可能比较小
5.多副本的机制简单很多
14.kafka是怎么做到消息顺序性的
消息顺序 {1,2,3,4,5} 生产端肯定是单线程, 确定一个主题(只有一个分区partition),
保证一个主题里只有一个分区才可以。并且只有一个消费者。
15.kafka为什么那么快
1.存储:文件存储。文件顺序读写。(接近于内存)
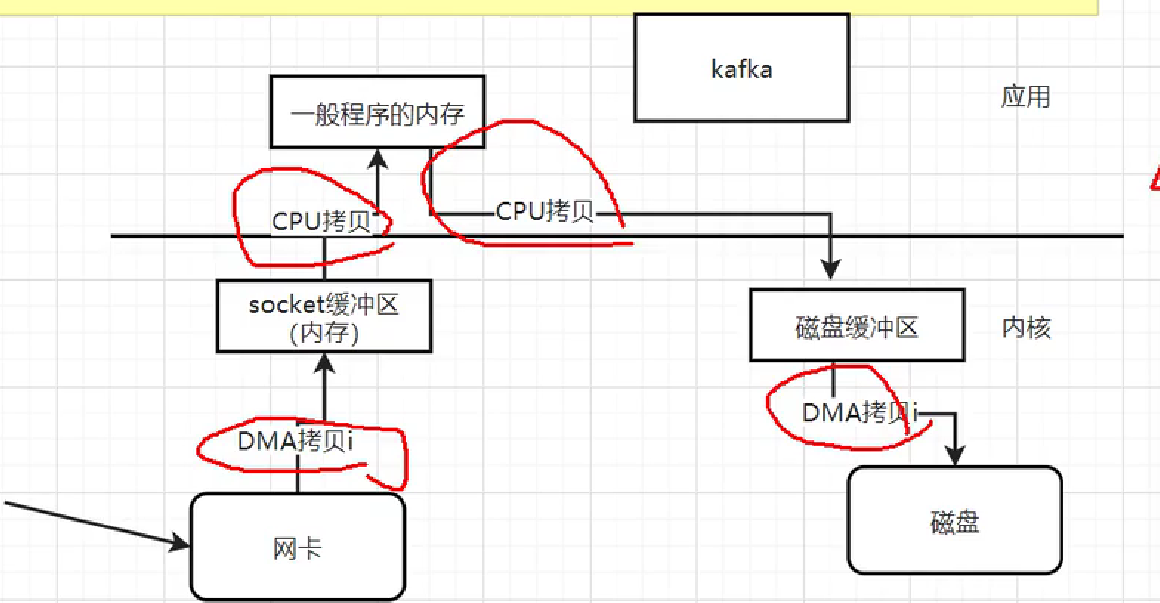
2.写入数据: 传统的4次拷贝,零拷贝技术,减少没有必要的拷贝。 sendfile。数据->网卡->DMA拷贝->网络socket缓冲区(本质就是内核的内存)->CPU拷贝->socket缓冲区(一般程序应用的内存)->CPU拷贝->磁盘缓冲区->DMA拷贝->磁盘。
4次拷贝:
sendfile:文件描述符,在socket缓冲区中属于哪一段
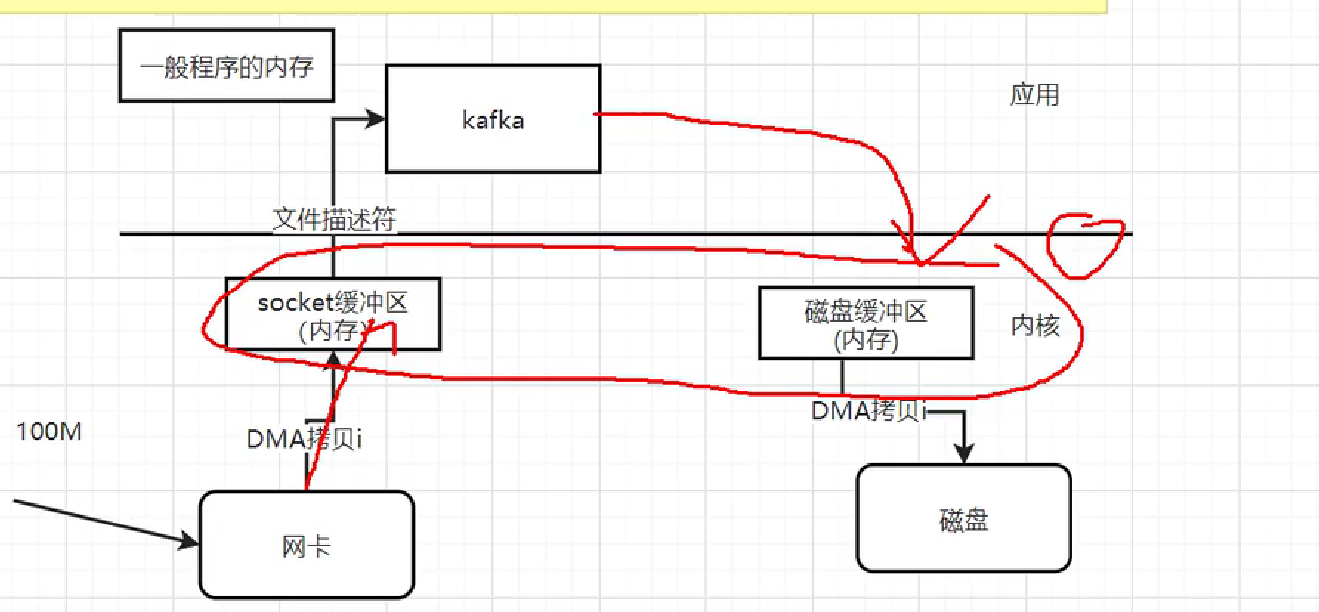
节约了两次CPU拷贝,将socket缓冲区和磁盘缓冲区放一起。
3.批量处理,压缩,json的话7倍。
16.如何解决重复消费
去保证一个幂等性
1.MVCC多版本并发控制(生产的时候带上数据的版本号)
2.去重表的方案:A表里只有一个唯一字段id, try{ insert A –>执行业务 } catch{异常不用抛出 ,吃掉异常}
17.RocketMQ如何保证高可用
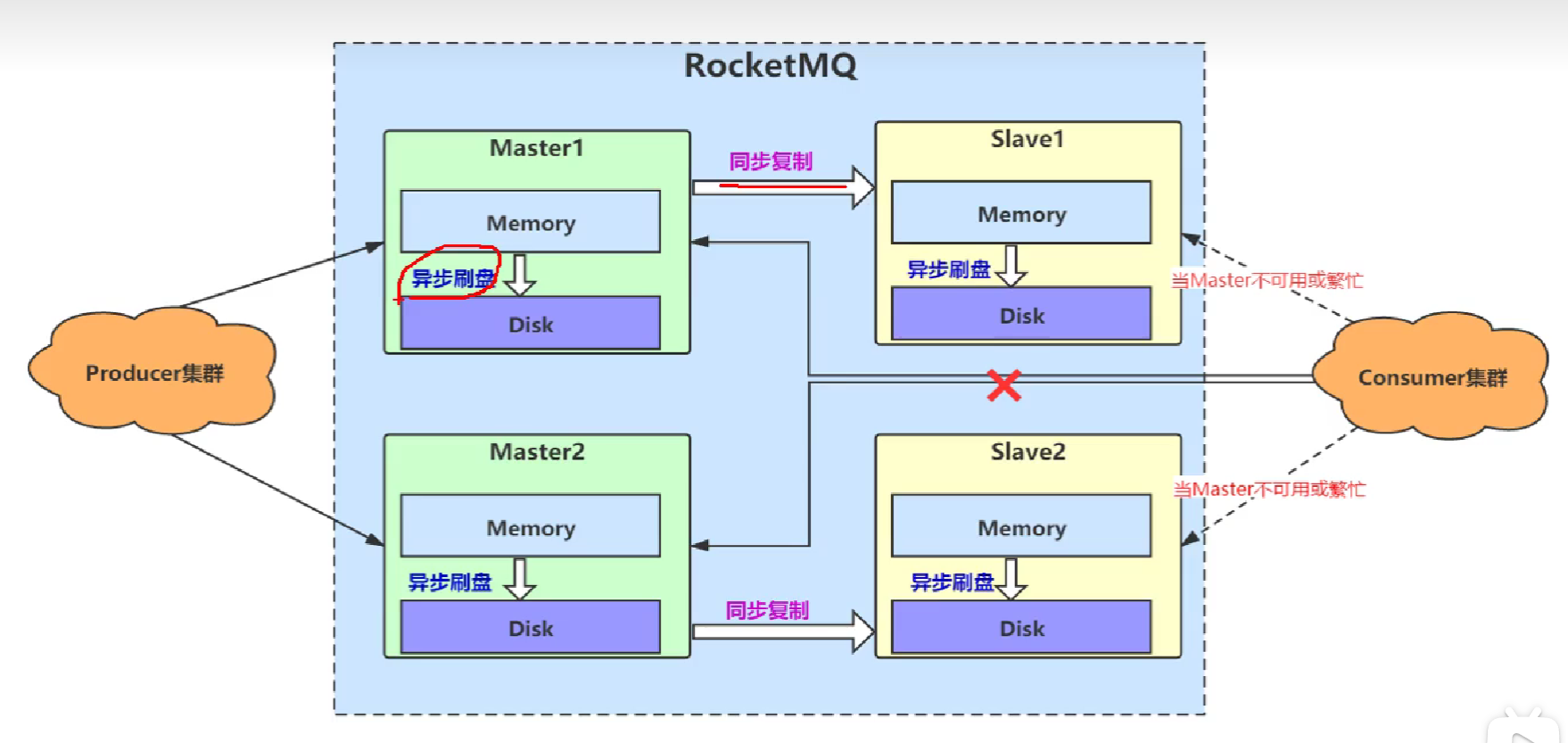
同步复制和异步刷盘。同步可以保证数据一定到从节点的内存。同步刷盘导致生产效率很低。
18.RocketMQ中的存储机制了解吗
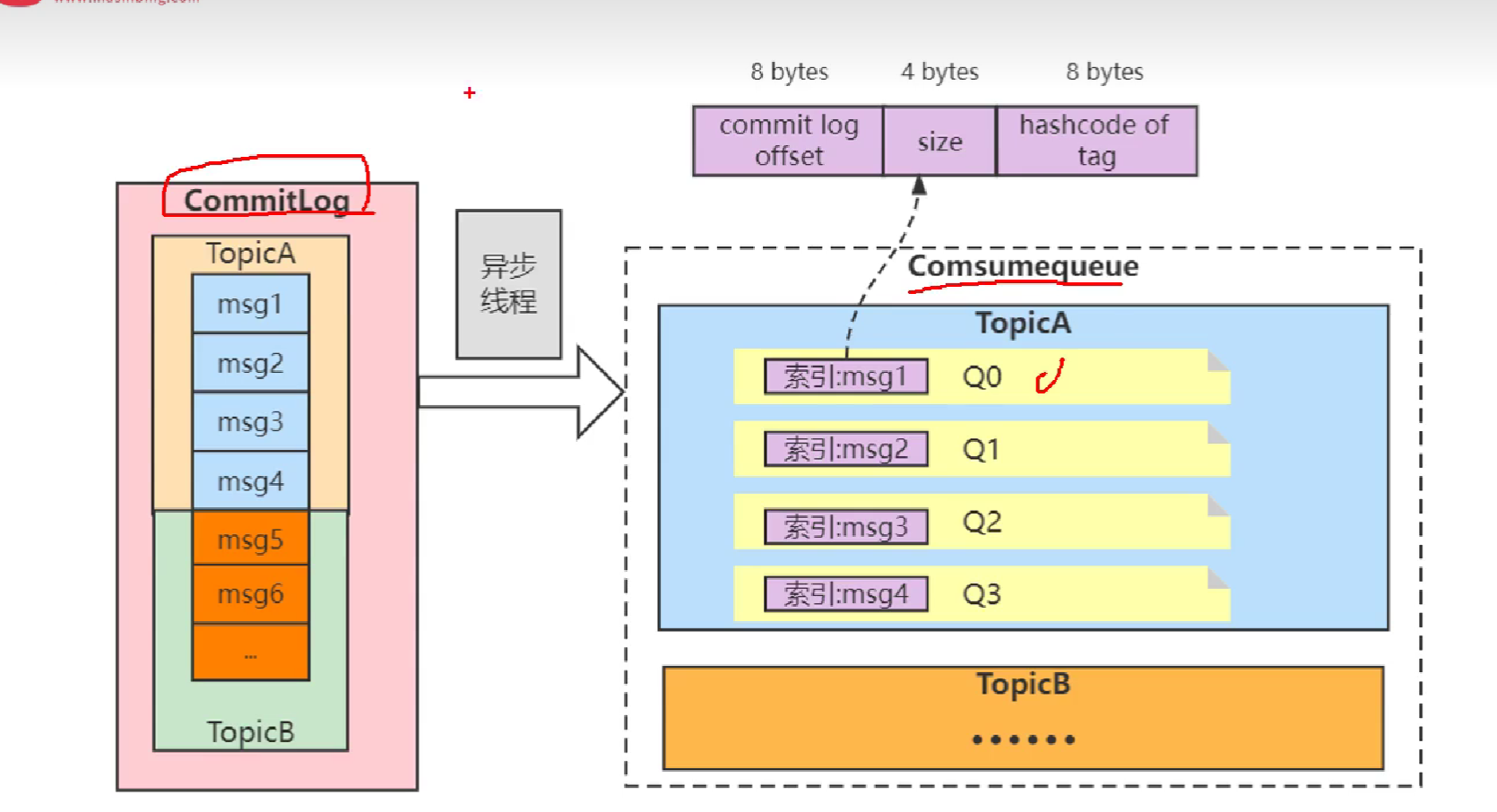
即使是一万个主题,也只有一个commitLog,如果有很多commitLog会造成海量的IO切换。Kafka好像就是多个commitLog,RcoketMQ更适合电商场景。
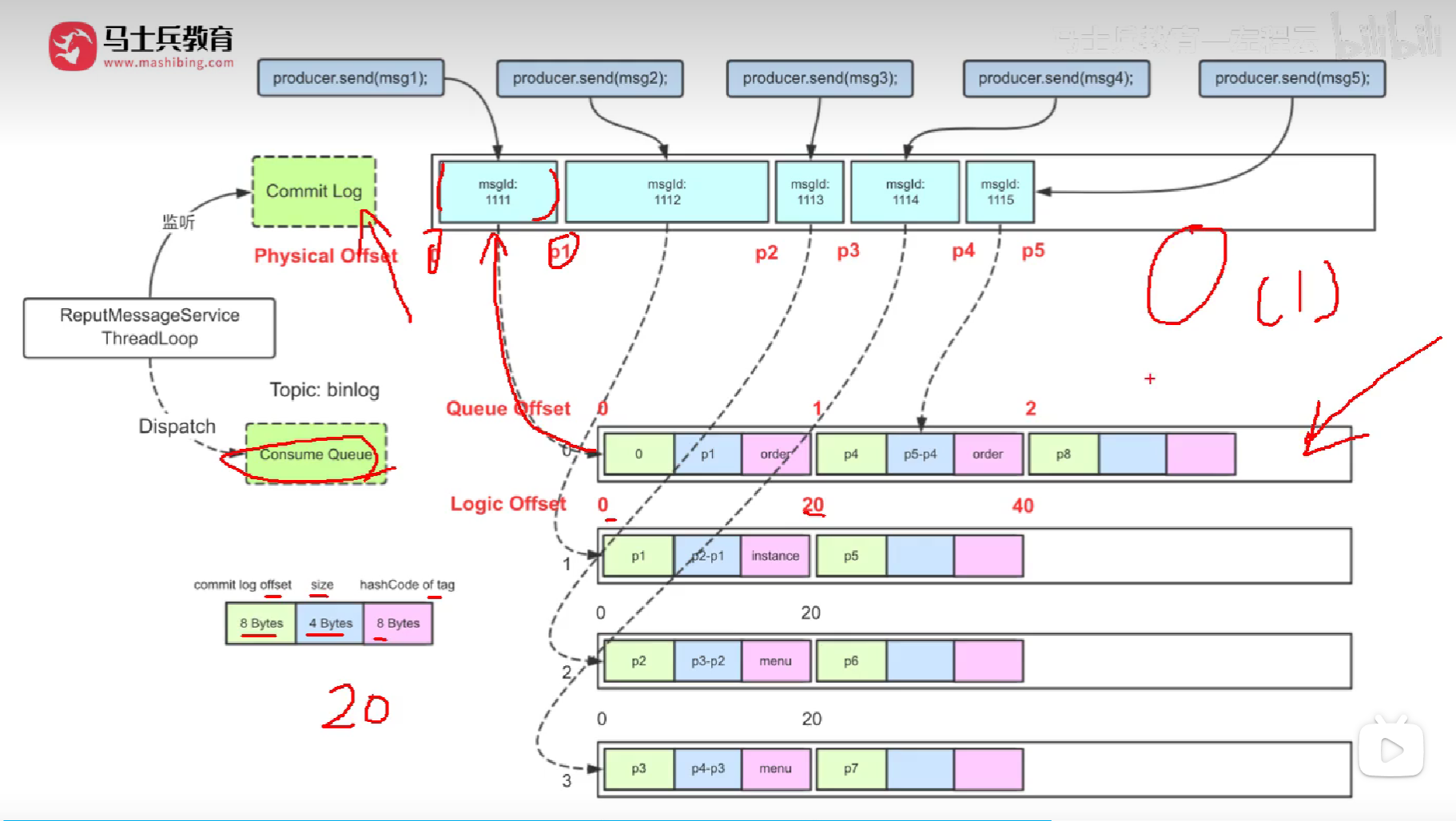
19.RocketMQ中性能比较高的原因
1.内部使用Netty这个高效的NIO通信框架
2.大量使用多线程和异步
3.采用零拷贝技术优化(MMAP) 性能提升50%
4.采用文件存储,顺序读写。接近内存的速度
5.锁优化(CAS机制无锁化)
6.存储设计:读写分离。
20.如何设计一个消息队列
存储:高可用-磁盘存储,顺序读写,零拷贝技术
可伸缩:分布式,参考Kafka, broker \topic\partition
消息的丢失:多主多从, 多副本,raft协议,一台主服务器宕机,选举机制。
消息重复设计
网络框架:Netty 高效的NIO框架。
21.有几百万消息持续积压几个小时,如何解决
分析:消息积压–线上故障(消费者)
1.修复消费者。有可能消耗几个小时
临时扩容。 多搞几个消费者。把3个队列里的东西快速的放到30个队列里
22.RocketMQ中Broker的部署方式
单机broker。
多Master。
多Master,多Slave.
24.什么是路由注册,路由发现,路由剔除
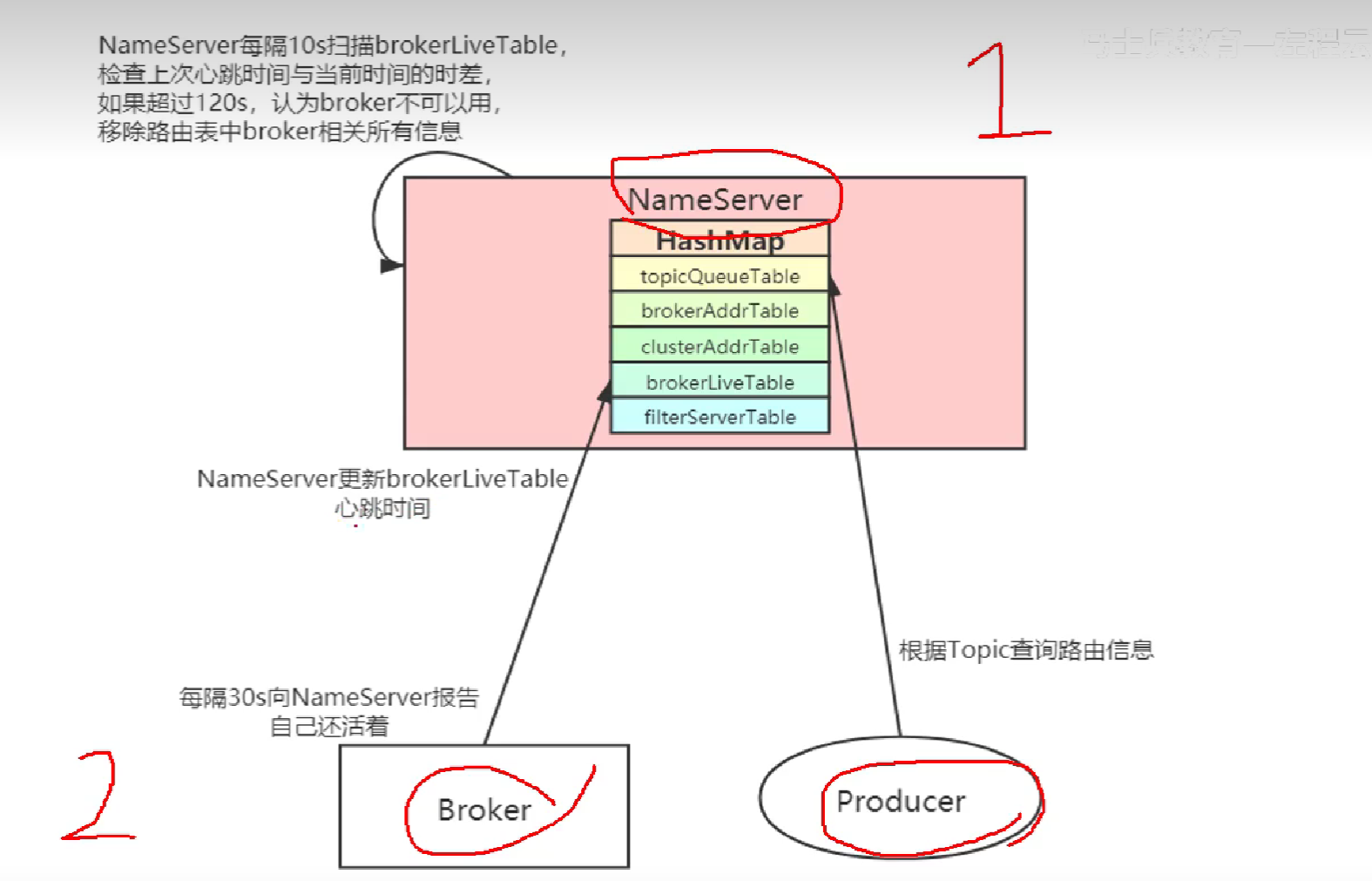
NameSever不会主动,每隔30秒Producer主动去拉。
路由就是broker.
27.使用RocketMQ过程中遇到的问题
为了高可用,要搭建主从
消费者大于queue的数量,最后的消费者拿不到queue.一个queue不能给多个消费者消费。
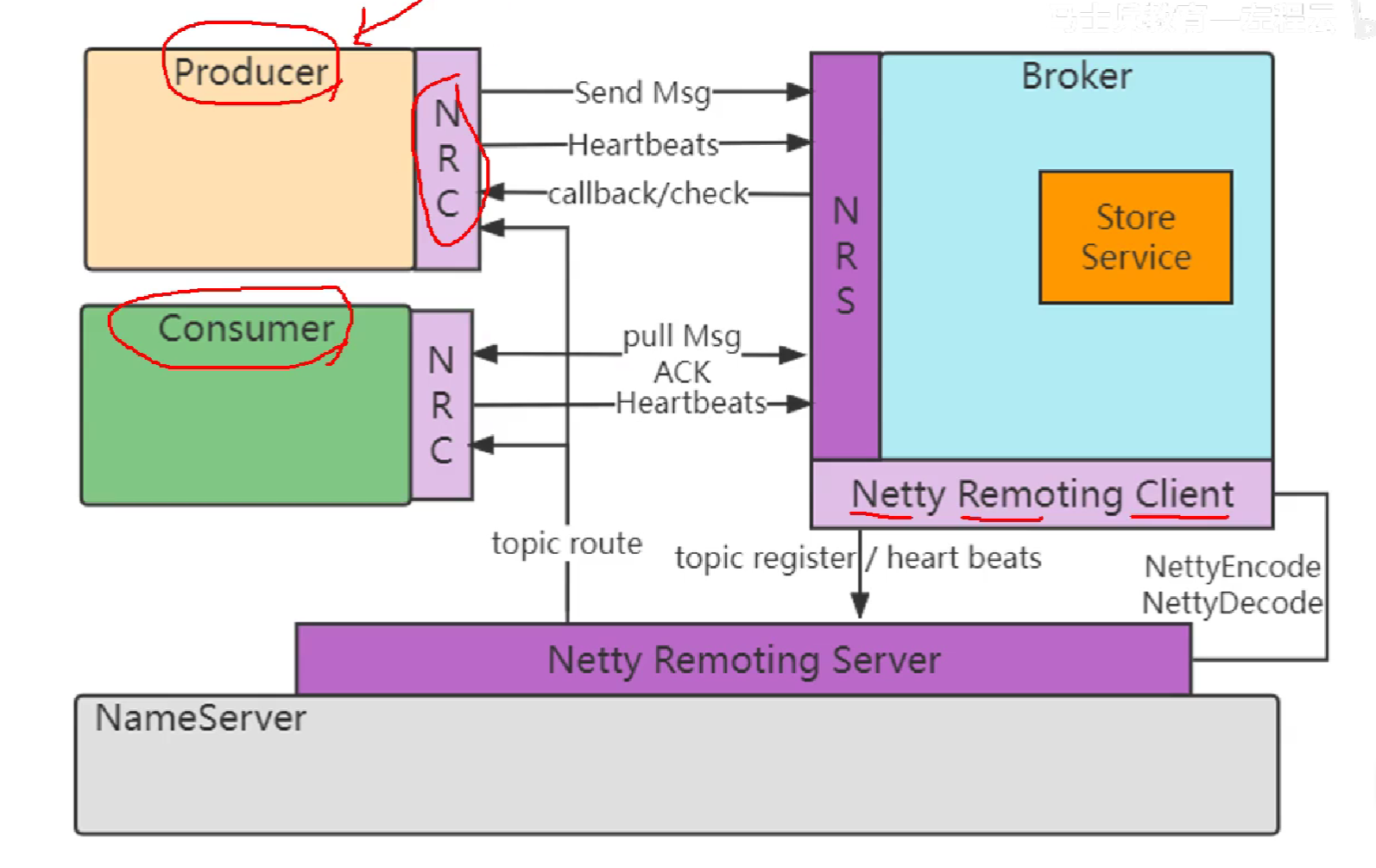
28.RocketMQ的总体架构,以及其中各个组件的功能
Netty负责网络通讯,store负责零拷贝存储。
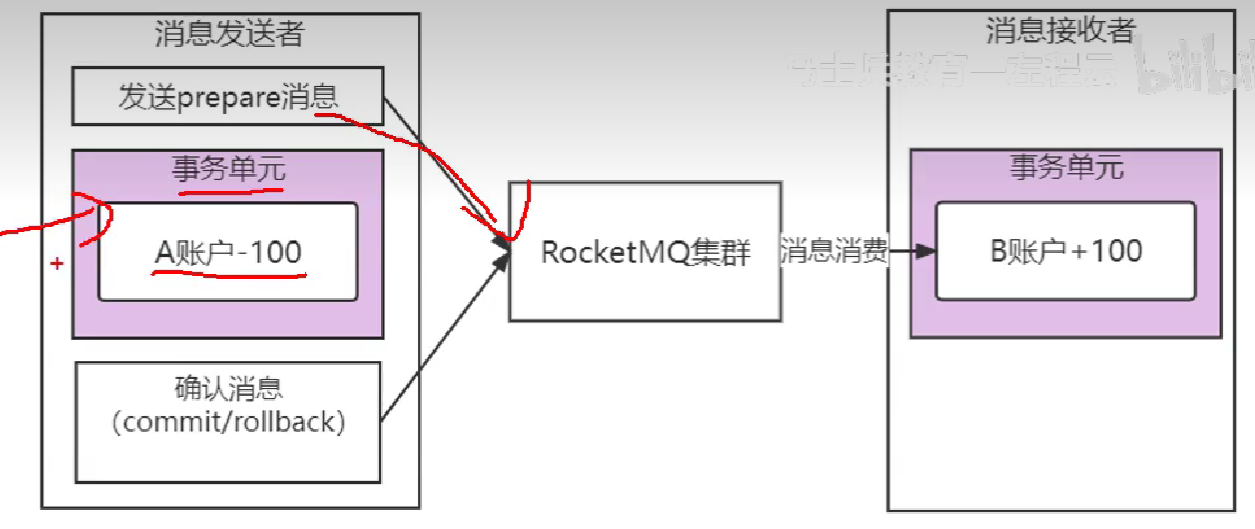
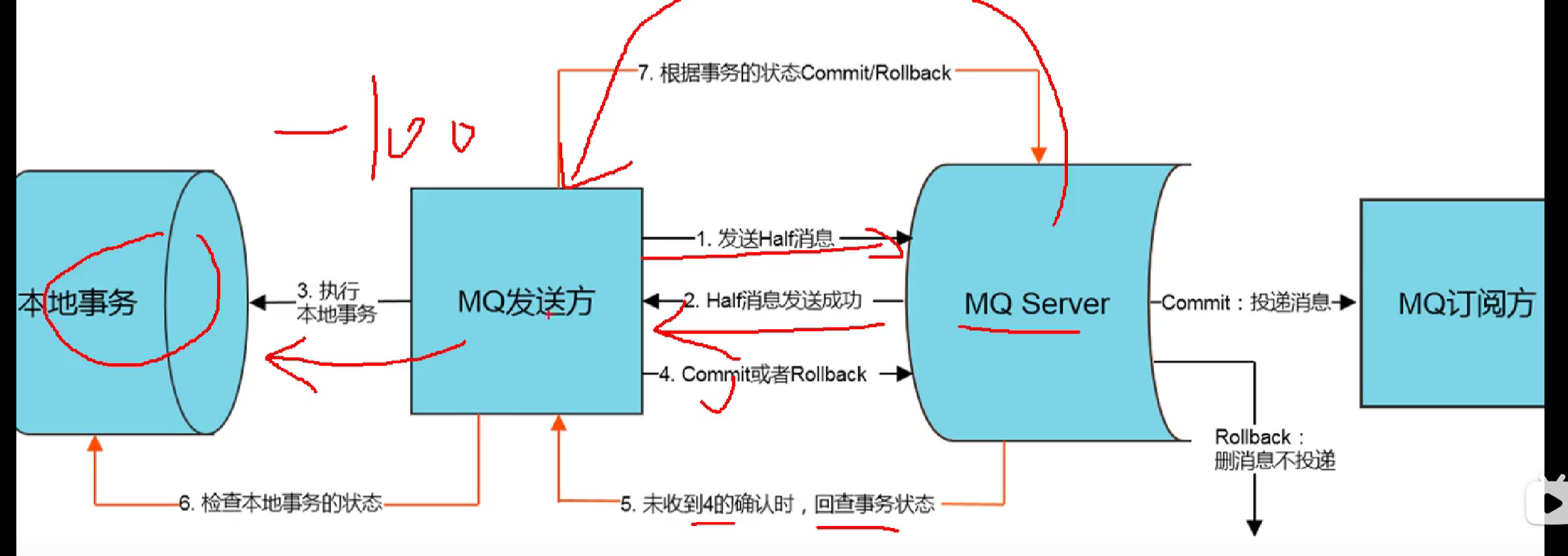
29.讲一讲RocketMQ中的分布式事务及其实现
银行转账,A->B。
A账户 -100 SQL事务,B账户 +100 SQL事务
两阶段提交,半消息。MQ的消费者本身就会不断重试。