EffectiveJava读后感
1.考虑以静态工厂方法代替构造函数
这个在实习项目中也用到过,比如XML的内部类里
/**
* 红字发票
*/
@Data
public class RedEInvoice{
/**
* 被红冲蓝字数电发票号码(备注)
*/
String OriginlInvoiceCode;
/**
* 红字发票信息确认单编号
*/
String CreditNoteNumber;
}
public RedEInvoice getRedEInvoiceInstance(){
return new RedEInvoice();
}
因为红字发票类是内部类,外面拿不到。所以只能用这种getInstance的方法。
但其实这也不是静态方法,因为仍然是每次新构建对象。静态工厂应该只有一个对象。
2.(用的不多?)面对许多构造函数参数时,考虑构建器
不想写一大堆不同的构造函数,又不想一个个调用set函数。可以考虑使用构建器,它既保证线程安全,又能提供较好的可读性。
// Builder Pattern
public class NutritionFacts {
private final int servingSize;
private final int servings;
private final int calories;
private final int fat;
private final int sodium;
private final int carbohydrate;
public static class Builder {
// Required parameters
private final int servingSize;
private final int servings;
// Optional parameters - initialized to default values
private int calories = 0;
private int fat = 0;
private int sodium = 0;
private int carbohydrate = 0;
public Builder(int servingSize, int servings) {
this.servingSize = servingSize;
this.servings = servings;
}
public Builder calories(int val) {
calories = val;
return this;
}
public Builder fat(int val) {
fat = val;
return this;
}
public Builder sodium(int val) {
sodium = val;
return this;
}
public Builder carbohydrate(int val) {
carbohydrate = val;
return this;
}
public NutritionFacts build() {
return new NutritionFacts(this);
}
}
private NutritionFacts(Builder builder) {
servingSize = builder.servingSize;
servings = builder.servings;
calories = builder.calories;
fat = builder.fat;
sodium = builder.sodium;
carbohydrate = builder.carbohydrate;
}
public static void main(String[] args) {
NutritionFacts cocaCola = new NutritionFacts.Builder(240, 8)
.calories(100).sodium(35).carbohydrate(27).build();
}
}
3.使用私有构造函数或枚举类型实现单例属性
其中私有构造函数,其实还是要借助静态变量和静态函数。
4.用私有构造函数保证不可实例化
有些Java类我们不想实例化,只想调用它的静态方法,一般是对于一些工具类,如java.lang.Math 或 java.util.Arrays。
为了保证非实例化,我们可以将构造函数设为私有,这样使用者就没法实例化这个类了
5.依赖注入优于硬连接资源
@Resource(name=””)应该就是一种依赖注入,想注入啥就注入啥。
6.避免创建不必要的对象
下面语句会创建两个String对象:
String s = new String("bikini"); // DON'T DO THIS!
换一种写法就只会创建一个:
String s = "bikini";
也可以使用静态工厂来避免创建不必要的对象,如:Boolean.valueOf(String)
也可以将创建的对象缓存以备复用。比如自动装箱。
7.清除过时的对象引用
对于一个堆栈的实现,你不应该这样:
public Object pop() {
if (size == 0)
throw new EmptyStackException();
return elements[--size];
}
应该要考虑把引用也删掉:
public Object pop() {
if (size == 0)
throw new EmptyStackException();
Object result = elements[--size];
elements[size] = null; // Eliminate obsolete reference
return result;
}
在被数组,MAP引用的时候这种情况容易发生。或者缓存忘记删除也会一直占用内存。
有两种解决办法:
使用WeakHashMap。WeakHashMap当key没有再被外部引用时,条目会自动从WeakHashMap中删除。
采用缓存清除策略。典型的如LinkedHashMap实现的LRU。
WeakHashMap原理简析:
- 添加entry时,设置entry为弱引用,指向这个entry的key,并将这个弱引用注册到referenceQueue上
- 当key没有被外部引用时,GC触发时回收key,并导致entry(弱引用)被添加到referenceQueue中 。
- 当调用任意访问WeakHashMap的方法时,会触发expungeStaleEntries方法,将entry从WeakHashMap中移除。
8.避免使用终结器和清除器
Finalizer和Cleaner通常是不必要、危险而且不可预测的。Finalizer在Java 9中已经被弃用,在后面的版本中用Cleaner替代Finalizer。前者比后者的危险小。
Finalizer和Cleaner不能被保证立即执行,它们的执行时间取决于具体的GC实现。而且使用它们会严重影响性能。
9.使用 try-with-resources 优于 try-finally
用try-finally关闭资源,会使得代码可读性差,而且容易出错,特别是在关闭多个资源的时候。
// try-finally is ugly when used with more than one resource!
static void copy(String src, String dst) throws IOException {
InputStream in = new FileInputStream(src);
try {
OutputStream out = new FileOutputStream(dst);
try {
byte[] buf = new byte[BUFFER_SIZE];
int n;
while ((n = in.read(buf)) >= 0)
out.write(buf, 0, n);
} finally {
out.close();
}
}
finally {
in.close();
}
}
如果用try-with-resources就简单多了,且不易出错
static void copy(String src, String dst) throws IOException {
try (InputStream in = new FileInputStream(src);OutputStream out = new FileOutputStream(dst)) {
byte[] buf = new byte[BUFFER_SIZE];
int n;
while ((n = in.read(buf)) >= 0)
out.write(buf, 0, n);
}
}
10.覆盖 equals 方法时应遵守通用约定
11.当覆盖 equals 方法时,总要覆盖 hashCode 方法
当覆盖equals方法时,必须要覆盖hashCode方法。因为相等的对象必须要有相同的哈希码。
Map<PhoneNumber, String> m = new HashMap<>();
m.put(new PhoneNumber(707, 867, 5309), "Jenny");
在上面的例子执行后,你可能期望 m.get(new PhoneNumber(707, 867,5309)) 返回”Jenny”,但是它返回 null。原因是用于检索的新对象虽然与旧对象相等,但是它们的哈希码不同,因此哈希码对应的哈希桶也不同,所以再也找不到了。
12.始终覆盖 toString 方法
13.明智地覆盖 clone 方法
Object类中实现了clone方法,这个方法是native的,所做操作是浅拷贝,即把原对象完整拷贝过来并包括其中的引用。
我感觉还是用BeanUtils.copyProperties去复制属性比较好。
14.考虑实现 Comparable 接口
public interface Comparable<T> {
int compareTo(T t);
}
如果你需要让类支持排序,那么就要实现Comparable接口。
或者实现Comparator接口
排序的另一种实现方式是实现Comparator接口,性能大概比Comparable慢10%,例如:
// Comparable with comparator construction methods
private static final Comparator<PhoneNumber> COMPARATOR = comparingInt((PhoneNumber pn) -> pn.areaCode)
.thenComparingInt(pn -> pn.prefix)
.thenComparingInt(pn -> pn.lineNum);
public int compareTo(PhoneNumber pn) {
return COMPARATOR.compare(this, pn);
}
有时人们会用计算差值的方法来实现compare方法,例如:
// BROKEN difference-based comparator - violates transitivity!
class DateWrap{
Date date;
}
static Comparator<DateWrap> order = new Comparator<>() {
public int compare(DateWrap d1, DateWrap d2) {
return d1.date.getTime() - d2.date.getTme();
}
};
但是这种做法是有缺陷的。在上例中,Date.getTime返回long型时间戳,两者的差值有可能溢出int。所以应该用Date类自带的比较方法:
// Comparator based on static compare method s
static Comparator<DateWrap> order = new Comparator<>() {
public int compare(DateWrap d1, DateWrap d2) {
return d1.date.compareTo(d2.date);
}
};
15.尽量减少类和成员的可访问性
对于成员(字段、方法、嵌套类和嵌套接口),存在四种访问级别,按可访问性从低到高分别是:
- 私有(private):成员只能从声明它的顶级类访问。
- 包级(package-private):成员可以从声明它的类所在的包访问。不加修饰符时默认的访问级别。
- 保护(protected):成员可以从声明它的类的子类和声明它的类所在的包访问。
- 公共(public):成员可以从任意地方访问。
| 修饰符 | 类内部 | 同个包(package) | 子类 | 其他范围 |
|---|---|---|---|---|
| public | Y | Y | Y | Y |
| protected | Y | Y | Y | N |
| 无修饰符 | Y | Y | Y or N | N |
| private | Y | N | N | N |
需要特别说明“无修饰符”这个情况,子类能否访问父类中无修饰符的变量/方法,取决于子类的位置。如果子类和父类在同一个包中,那么子类可以访问父类中的无修饰符的变量/方法,否则不行。
16.在公共类中,使用访问器方法,而不是公共字段
应该通过setter、getter方法访问。
17.减少可变性
不可变类是实例不能被修改的类。Java中有很多不可变类,如String、Integer等。不可变类的优点是:简单、线程安全,可作为缓存共享。
不可变类的缺点是每个不同的值都需要一个单独的对象。这样会产生很多对象创建和回收的开销。解决办法是提供一个公共可变伴随类。例如String的公共可变伴随类就是StringBuilder,用后者处理多个字符串的拼接时可以减少对象创建数量。
18.优先选择组合而不是继承
19.继承要设计良好并且具有文档,否则禁止使用
20.接口优于抽象类
接口相对抽象类的优点是:
- 一个类只能继承单个抽象类,却能实现多个接口。
- 接口的使用更加灵活,可以很容易对现有类进行改造,实现新的接口。
- 接口允许构造非层次化类型结构。示例如下,有一个歌手接口和一个歌曲作者接口:
public interface Singer { AudioClip sing(Song s); }
public interface Songwriter { Song compose(int chartPosition); }
如果有人既是歌手,又是歌曲作者,那么我们通过创建一个新的接口就能很容易实现这个需求:
public interface SingerSongwriter extends Singer, Songwriter {
AudioClip strum();
void actSensitive();
}
为了代码复用,可以为接口提供默认方法。但是默认方法有不少限制,例如编译器会阻止你提供一个与Object类中的方法重复的默认方法,而且接口不允许包含实例字段或非公共静态成员(私有静态方法除外)。
这时可以实现一个抽象骨架类来结合抽象类和接口的优点。例如Java类库中的AbstractList就是典型的抽象骨架类。抽象骨架类使用了设计模式中的模板模式。
在模板模式(Template Pattern)中,一个抽象类公开定义了执行它的方法的方式/模板。它的子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行。这种类型的设计模式属于行为型模式。
public abstract class Game {
abstract void initialize();
abstract void startPlay();
abstract void endPlay();
//模板
public final void play(){
//初始化游戏
initialize();
//开始游戏
startPlay();
//结束游戏
endPlay();
}
}
你去继承Game类,然后重写其中的initialize(),startPlay(),endPlay()方法。但是最后调用play()函数的执行顺序肯定是按模版去走的。
21.为后代设计接口
接口的默认方法可能不适用于后代,要谨慎。
22.接口只用于定义类型
接口只应该用来定义类型,不要用来导出常量。
23.类层次结构优于带标签的类
类层次结构,三个类:图形,圆继承自图形,方形继承自图形
带标签的类:一个类大杂烩。
24.静态成员类优于非静态成员类
嵌套类共有四种:静态成员类、非静态成员类、匿名类和局部类。它们各自有不同的适用场合。判断方法见如下流程图:
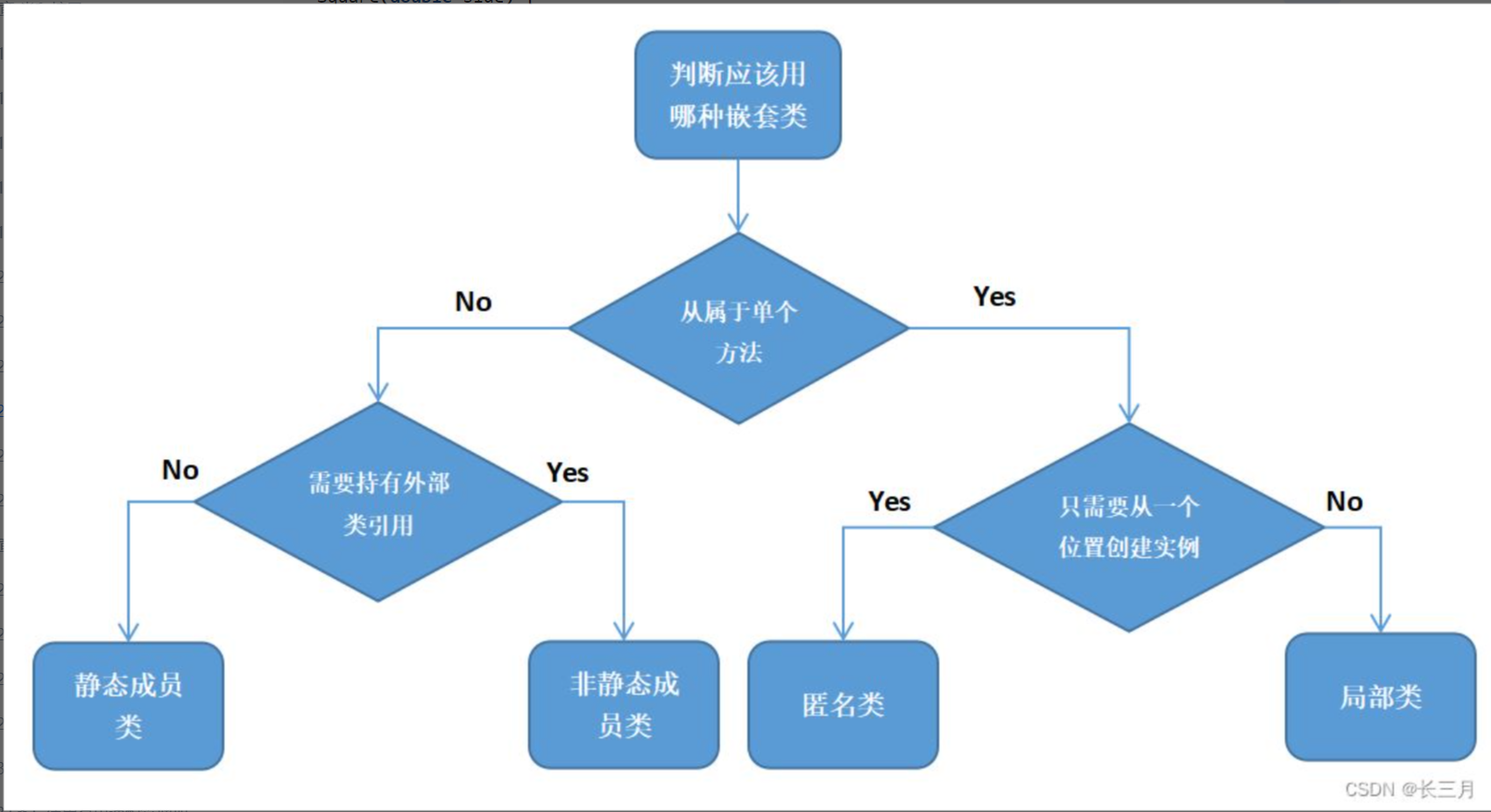
每种嵌套类的常见例子总结如下:
- 静态成员类:作为公共的辅助类,如Map中的Entry类。
- 非静态成员类:Map的entrySet、keySet方法返回的视图,List、Set中的迭代器。
- 匿名类:新建Comparable、Runnable接口实现类,可用lambda表达式替代。
- 局部类:与匿名类的区别仅为有名字,可重复使用。
下面重点谈谈静态成员类和非静态成员类的取舍。如果成员类不需要访问外部实例,那么始终应该设置其为静态的。因为非静态的成员类会持有对外部类的引用,增加时间空间代价,而且会影响对外部类的垃圾回收。
25.源文件仅限有单个顶层类
26.不要使用原始类型
例如,List<E> 对应的原始类型是 List。
private static void unsafeAdd(List list, Object o) {
list.add(o);
}
如果你想使用泛型,但不知道或不关心实际的类型参数是什么,那么可以使用问号代替。例如,泛型集合 Set<E> 的无界通配符类型是 Set<?>。它是最通用的参数化集合类型,能够容纳任何集合:
// Uses unbounded wildcard type - typesafe and flexible
static int numElementsInCommon(Set<?> s1, Set<?> s2) { ... }
27.消除 unchecked 警告
使用泛型编程时,很容易看到unchecked编译器警告。我们应该尽可能消除这些警告。消除所有这些警告后,我们就能确保代码是类型安全的。
但有时警告无法消除,如果我们可以证明代码是类型安全的,可以通过SuppressWarnings(“unchecked”) 注解来抑制警告。
28.list 优于数组
29.优先使用泛型类型
应该尽量在自己编写的类型中使用泛型,这会保证类型安全,并使代码更易使用。
下面我们通过例子来看下如何对一个现有类做泛型化改造。
private Object[] elements;
public Stack() {
elements = new Object[DEFAULT_INITIAL_CAPACITY];
}
我们用适当的类型参数替换所有的 Object 类型,然后尝试编译修改后的程序
private E[] elements;
public Stack() {
elements = new E[DEFAULT_INITIAL_CAPACITY];
}
这时生成一个错误,讲到不能创建一个非具体化类型的数组。因此我们修改为:
@SuppressWarnings("unchecked")
public Stack() {
elements = (E[]) new Object[DEFAULT_INITIAL_CAPACITY];
}
30.优先使用泛型方法
31.使用有界通配符增加 API 的灵活性
考虑第29条中的堆栈类。我们创建一个Stack<Number>类型的堆栈,并在其中插入integer。
Stack<Number> numberStack = new Stack<>();
Iterable<Integer> integers = ... ;
numberStack.pushAll(integers);
这个例子在直觉上似乎是没问题的。然而实际执行的时候会报错。
解决办法是使用带extends的有界通配符类型。下面代码表示泛型参数为E的子类型(包括E类型本身):
// Wildcard type for a parameter that serves as an E producer
public void pushAll(Iterable<? extends E> src) {
for (E e : src)
push(e);
}
解决办法是使用带super的有界通配符类型。下面例子表示泛型参数为E的超类(包括E类型本身)。
// Wildcard type for parameter that serves as an E consumer
public void popAll(Collection<? super E> dst) {
while (!isEmpty()
dst.add(pop());
}
总结上面例子的经验,就是生产者用extends通配符,消费者用super通配符。
32.明智地合用泛型和可变参数
33.考虑类型安全的异构容器
泛型部分太难了呜呜呜。
34.用枚举类型代替 Int 常量
一般单独用一个临时的常数变量用Int,有多个类似的常量参数用枚举。
枚举类型相比int常量有不少优点,如:能提供类型安全性,能提供toString方法打印字符串,还允许添加任意方法和字段并实现任意接口,使得枚举成为功能齐全的抽象(富枚举类型)。
一般来说,枚举在性能上可与 int 常量相比,不过加载和初始化枚举类型需要花费空间和时间,实际应用中这一点可能不太明显。
35.使用实例字段替代序数
36.用 EnumSet 替代位字段
37.使用 EnumMap 替换序数索引
用序数索引数组不如使用 EnumMap ,应尽量少使用 ordinal()
38.使用接口模拟可扩展枚举
39.注解优于命名模式
40.坚持使用 @Override 注解
41.使用标记接口定义类型
42.λ 表达式优于匿名类
匿名类:
// Anonymous class instance as a function object - obsolete!
Collections.sort(words, new Comparator() {
public int compare(String s1, String s2) {
return Integer.compare(s1.length(), s2.length());
}
});
lambda表达式
Collections.sort(words,(s1, s2) -> Integer.compare(s1.length(), s2.length()));
43.方法引用优于 λ 表达式
方法引用通常比lambda 表达式更简洁,应优先使用。
下面一个程序的代码片段的功能是:如果数字 1 不在映射中,则将其与键关联,如果键已经存在,则将关联值递增:
map.merge(key, 1, (count, incr) -> count + incr);
在 Java 8 中,Integer类提供了一个静态方法 sum,它的作用完全相同,且更简单:
map.merge(key, 1, Integer::sum);
如果 lambda 表达式太长或太复杂,那么可以将代码从 lambda 表达式提取到一个新方法中,并以对该方法的引用替换 lambda 表达式。可以为该方法起一个好名字并将其文档化.
44.优先使用标准函数式接口
如果一个标准的函数式接口可以完成这项工作,那么你通常应该优先使用它,而不是使用专门构建的函数式接口。
java.util.function 中有 43 个接口。可以只用记住 6 个基本接口,其余的接口在需要时派生出来:
- Operator 接口:表示结果和参数类型相同的函数。(根据参数数量可分为一元、二元)
- Predicate 接口:表示接受参数并返回布尔值的函数。
- Function 接口:表示参数和返回类型不同的函数。
- Supplier 接口:表示一个不接受参数并返回值的函数。
- Consumer 接口:表示一个函数,该函数接受一个参数,但不返回任何内容,本质上是使用它的参数。
六个基本的函数式接口总结如下:
| 接口 | 方法签名 | 例子 |
|---|---|---|
| UnaryOperator |
T apply(T t) | String::toLowerCase |
| BinaryOperator |
T apply(T t1, T t2) | BigInteger::add |
| Predicate |
boolean test(T t) | Collection::isEmpty |
| Function<T,R> | R apply(T t) | Arrays::asList |
| Supplier |
T get() | Instant::now |
| Consumer |
void accept(T t) | System.out::println |
45.明智地使用流
46.在流中使用无副作用的函数
47.优先选择 Collection 而不是流作为返回类型
48.谨慎使用并行流
并行性能带来明显性能提升的场合:
- ArrayList、HashMap、HashSet 和 ConcurrentHashMap 实例
- 数组
- 有界的IntStream和LongStream
这些数据结构的共同之处是:
可以被精确且廉价地分割成任意大小的子结构,这使得在并行线程之间划分工作变得很容易。
顺序处理时提供了良好的引用局部性(locality of reference)。引用局部性是指,当一个存储位置被处理器访问时,短时间内这个位置及附近位置被重复访问的趋势。良好的引用局部性可以充分利用处理器的多级缓存,带来性能提升。
绝大多数情况下,不要并行化流管道,除非通过测试证明它能保持计算的正确性以及提高性能。
49.检查参数的有效性
一些非空的判断,大于等于0的判断等
50.在需要时制作防御性拷贝
51. 仔细设计方法签名
仔细选择方法名字
提供便利的方法不应做过了头。 太多的方法会使得类难以维护。
避免长参数列表。 设定四个或更少的参数,有三种方法可以缩短过长的参数列表:
- 将原方法分解为多个子方法。原方法的功能由多个字方法组合实现,这样每个子方法只需要参数的一个子集。
- 创建 helper 类来保存参数组。
- 从对象构建到方法调用都采用建造者模式。
对于方法的参数类型,优先选择接口而不是类。例如优先选择Map而不是HashMap作为方法的参数类型。
对于方法的参数类型,优先选择双元素枚举类型而不是boolean 。枚举使代码更容易维护。此外,它们使以后添加更多选项变得更加容易。例如,你可能有一个Thermometer(温度计)类型与静态工厂,采用枚举:
public enum TemperatureScale { FAHRENHEIT, CELSIUS } // 华氏、摄氏
Thermometer.newInstance(TemperatureScale.CELSIUS) 不仅比 Thermometer.newInstance(true) 更有意义,而且你可以在将来的版本中向 TemperatureScale 添加 KELVIN(开尔文、热力学温标)。
52. 明智地使用重载overload
下面的程序是一个善意的尝试,根据一个 Collection 是 Set、List 还是其他的集合类型来进行分类:
// Broken! - What does this program print?
public class CollectionClassifier {
public static String classify(Set<?> s) {
return "Set";
}
public static String classify(List<?> lst) {
return "List";
}
public static String classify(Collection<?> c) {
return "Unknown Collection";
}
public static void main(String[] args) {
Collection<?>[] collections = {
new HashSet<String>(),new ArrayList<BigInteger>(),new HashMap<String, String>().values()
};
for (Collection<?> c : collections)
System.out.println(classify(c));
}
}
你期望的是:这个程序打印 Set、List 和 Unknown Collection,但结果是:它打印 Unknown Collection 三次。因为classify方法被重载,并且在编译时就决定了要调用哪个重载。
注意,重载(overload)方法的选择是静态的,而覆盖(override)方法的选择是动态的。
修复 CollectionClassifier 程序的最佳方法是用一个方法中用instanceof做类型判断:
public static String classify(Collection<?> c) {
return c instanceof Set ? "Set" :c instanceof List ? "List" : "Unknown Collection";
}
应该避免混淆重载的用法。最保守的策略是永远不生成具有相同参数数量的两个重载。或者为方法提供不同的名字,这样就可以不用重载。
53.明智地使用可变参数
可变参数方法接受指定类型的零个或多个参数。可变参数的底层是一个数组。
一个简单的可变参数例子:
// Simple use of varargs
static int sum(int... args) {
int sum = 0;
for (int arg : args)
sum += arg;
return sum;
}
建议只对三个以上参数进行可变参数
public void foo(int a1, int a2, int a3, int... rest) { }
而且还要判断可变参数是否为null
54.返回空集合或数组,而不是 null
如果新创建空集合会损害性能,那么可以通过重复返回空的不可变集合来避免新的创建:
如果你创建零长度数组会损害性能,你可以重复返回相同的零长度数组:
// Optimization - avoids allocating empty arrays
private static final Cheese[] EMPTY_CHEESE_ARRAY = new Cheese[0];
public Cheese[] getCheeses() {
return cheesesInStock.toArray(EMPTY_CHEESE_ARRAY);
}
55.明智地的返回 Optional
不应该在除方法返回值以外的任何地方使用Optional
56. 为所有公开的 API 元素编写文档注释
方法的文档注释应该简洁地描述方法与其调用者之间的约定,包括: 1. 说明方法做了什么,而不是如何做。 2. 应列举方法所有的前置条件和后置条件。 3. 说明方法产生的副作用。如启动一个新的后台线程。 4. 应包含必要的@param、@return 和@throw注释。
57.将局部变量的作用域最小化
将局部变量的作用域最小化,最有效的办法就是在第一次使用它的地方声明。
58.for-each 循环优于传统的 for 循环
for-each:
// The preferred idiom for iterating over collections and arrays
for (Element e : elements) {
... // Do something with e
}
但是有三种情况不应该使用for-each:
- 破坏性过滤:如果需要在遍历过程中删除元素,那么应该使用iterator和remove方法。Java 8中可以使用Collection类中提供的removeIf方法达到同样效果。
- 转换:如果需要在遍历List或者数组的时候替换其中部分元素的值,那么需要使用迭代器或者数组索引。
- 并行迭代:如果需要并行遍历多个容器,那么需要使用迭代器,自行控制迭代进度。
59. 了解并使用库
60.若需要精确答案就应避免使用 float 和 double 类型
61.基本数据类型优于包装类
下列场合应该使用包装类型,而不能使用基本类型:
- 作为容器中的元素、键和值。
- 参数化的类型和方法的类型参数。
- 在做反射方法调用时。
62.其他类型更合适时应避免使用字符串
63.当心字符串连接引起的性能问题
64.通过接口引用对象
如果存在合适的接口类型,那么应该使用接口类型声明参数、返回值、变量和字段。下面例子遵循了这个准则:
// Good - uses interface as type
Set<Son> sonSet = new LinkedHashSet<>();
65. 接口优于反射
反射机制java.lang.reflect提供对任意类的编程访问。反射提供的功能包括:
- 获取类的成员名、字段类型、方法签名。
- 构造类的实例,调用类的方法,访问类的字段。
- 允许一个类使用另一个编译时还不存在的类。
但是反射也有一些缺点:
- 失去了编译时类型检查的所有好处,包括异常检查。
- 执行反射访问时所需的代码比普通代码更加冗长。
- 反射方法调用比普通方法调用慢得多。
对于许多程序,它们必须用到在编译时无法获取的类。这时可以用反射创建实例,并通过它们的接口或超类访问它们。
66.明智地使用本地方法
67.明智地进行优化
68.遵守被广泛认可的命名约定
69.仅在有异常条件时使用异常
70.对可恢复情况使用受检异常,对编程错误使用运行时异常
Java 提供了三种可抛出项:受检异常(checked exception)、运行时异常(runtime exception)和错误(error)。
使用受检异常的情况是为了期望调用者能够从中恢复。其他两种可抛出项都是非受检的。
使用运行时异常来表示编程错误。 例如数组越界ArrayIndexOutOfBoundsException。如果对于选择受检异常还是运行时异常有疑问,那么推荐还是使用运行时异常。
错误保留给 JVM 使用,用于表示:资源不足、不可恢复故障或其他导致无法继续执行的条件。不要自己定义新的错误类型。
71.避免不必要地使用受检异常
72.鼓励复用标准异常
此表总结了最常见的可复用异常:
| Exception | Occasion for Use |
|---|---|
| IllegalArgumentException | 非null参数值不合适 |
| IllegalStateException | 对象状态不适用于方法调用 |
| NullPointerException | 禁止参数为null时仍传入 null |
| IndexOutOfBoundsException | 索引参数值超出范围 |
| ConcurrentModificationException | 在禁止并发修改对象的地方检测到并发修改 |
| UnsupportedOperationException | 对象不支持该方法调用 |
73.抛出与抽象级别相匹配的异常
74.为每个方法记录会抛出的所有异常
75.详细消息中应包含失败捕获的信息
76.尽力保证故障原子性
77.不要忽略异常
78.对共享可变数据的同步访问
volatile不保证变量读写的原子性,解决办法是使用原子变量。
79.避免过度同步
80. Executor、task、stream优于直接使用线程
81.并发实用工具优于wait-notify
直接使用wait-notify就像使用“并发汇编语言”编程一样原始,你应该使用更高级别的并发实用工具。比如ConcurrentHashMap.
对于间隔计时,始终使用 System.nanoTime 而不是 System.currentTimeMillis。 System.nanoTime 不仅更准确和精确,而且不受系统实时时钟调整的影响。
82.使线程安全文档化
83.明智地使用延迟初始化
在多线程竞争的情况下,使用延迟初始化容易导致错误。
84.不要依赖线程调度器
任何依赖线程调度器来保证正确性或性能的程序都无法保证可移植性。
85.优先选择 Java 序列化的替代方案
用于取代Java序列化,领先的跨平台结构化数据是JSON和Protobuf
86.非常谨慎地实现Serializable
实现Serializable接口会带来以下代价: 1. 一旦类的实现被发布,它就会降低更改该类实现的灵活性。需要永远支持序列化的形式。 2. 增加了出现 bug 和安全漏洞的可能性。 3. 它增加了与发布类的新版本相关的测试负担
87.考虑使用自定义序列化形式
transient修饰符表示要从类的默认序列化中省略该实例字段



