Redis原理篇-黑马
参考文章:https://blog.csdn.net/2301_77450803/article/details/130691756
动态字符串-SDS
C语言字符串存在很多问题:获取字符串长度的需要通过运算,非二进制安全,不可修改
SDS是一个结构体:当flag=1时,为uint8_t的类型
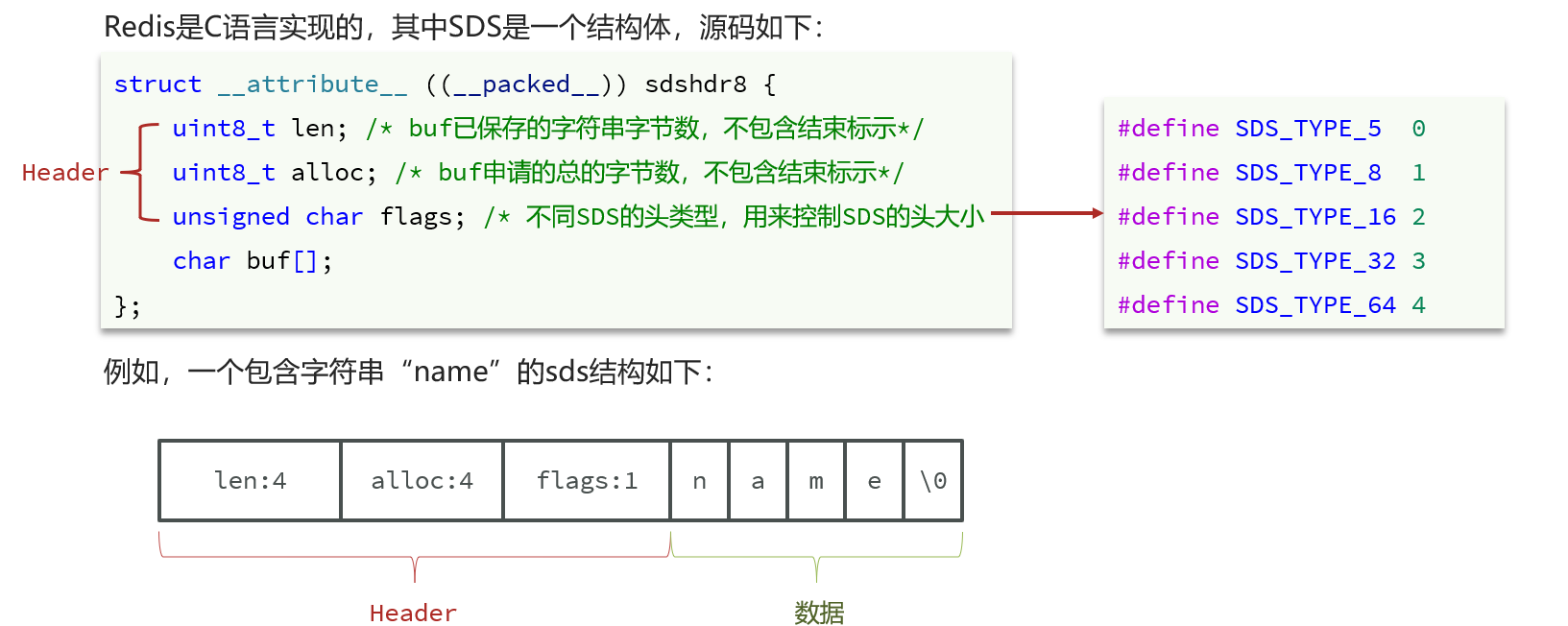
假如我们要给SDS追加一段字符串“,Amy”,这里首先会申请新内存空间:
如果新字符串小于1M,则新空间为扩展后字符串长度的两倍+1;
如果新字符串大于1M,则新空间为扩展后字符串长度+1M+1。称为内存预分配
SDS的优点:
①获取字符串长度的时间复杂度为O(1)
②支持动态扩容
③减少内存分配次数
④二进制安全
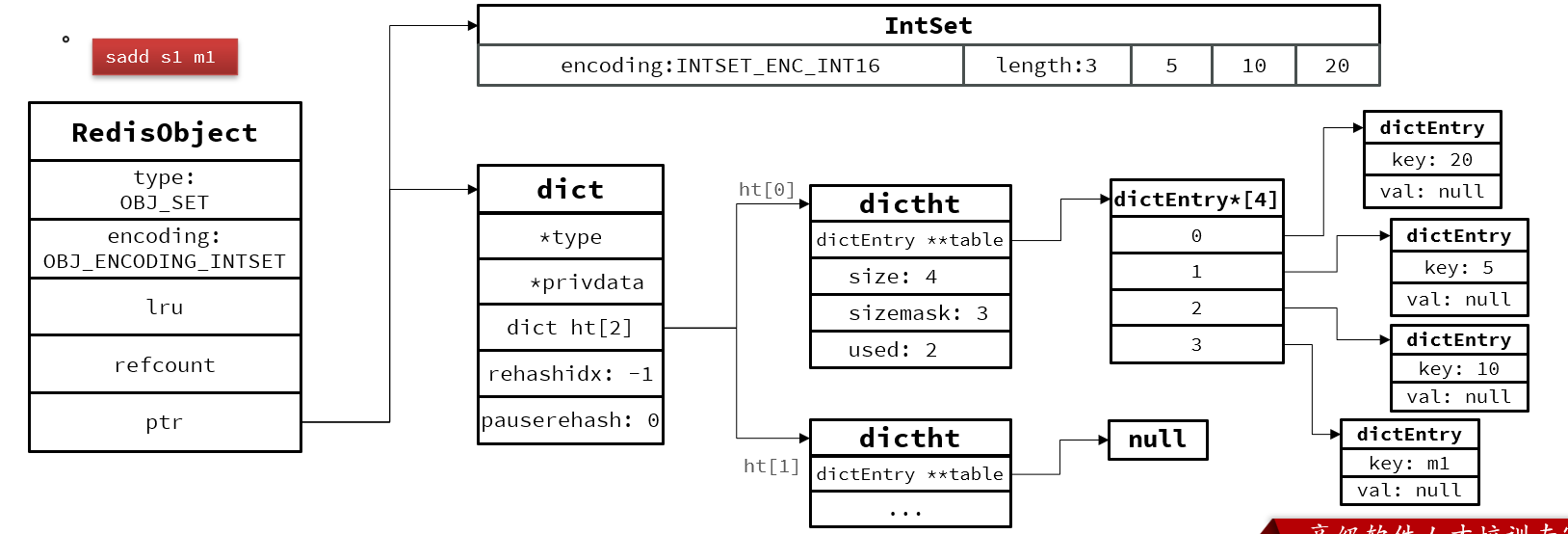
IntSet

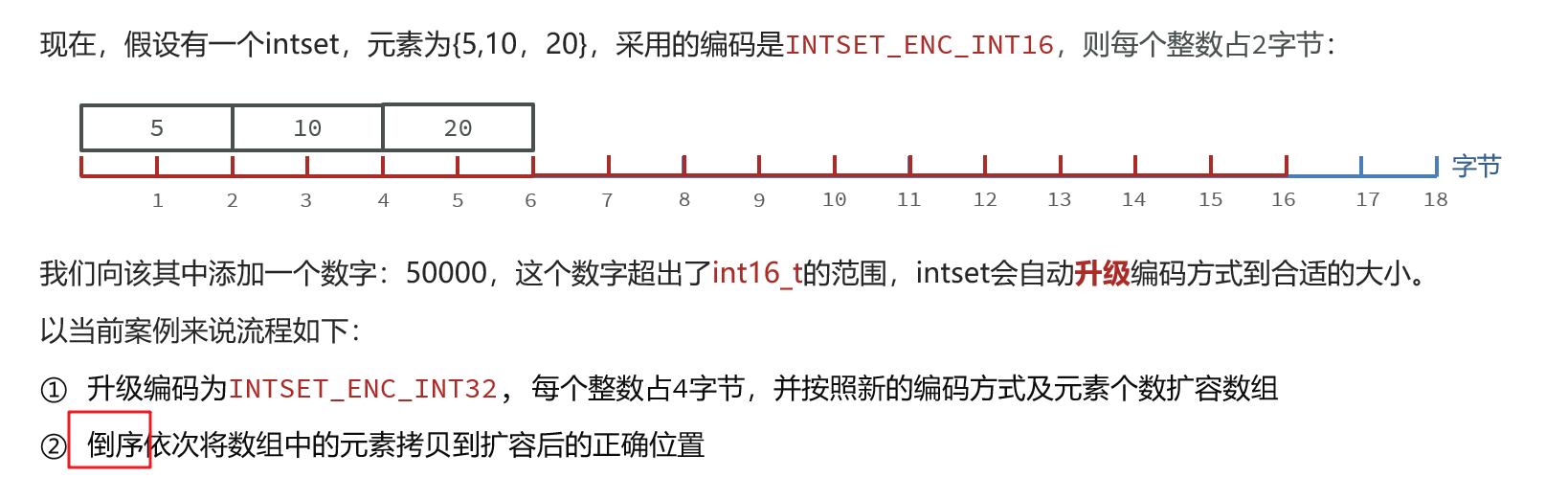
先把20放到合适的位置,再放10,再放5.

Intset的一些特点:
①Redis会确保Intset中的元素唯一、有序
②具备类型升级机制,可以节省内存空间
③底层采用二分查找方式来查询
Dict

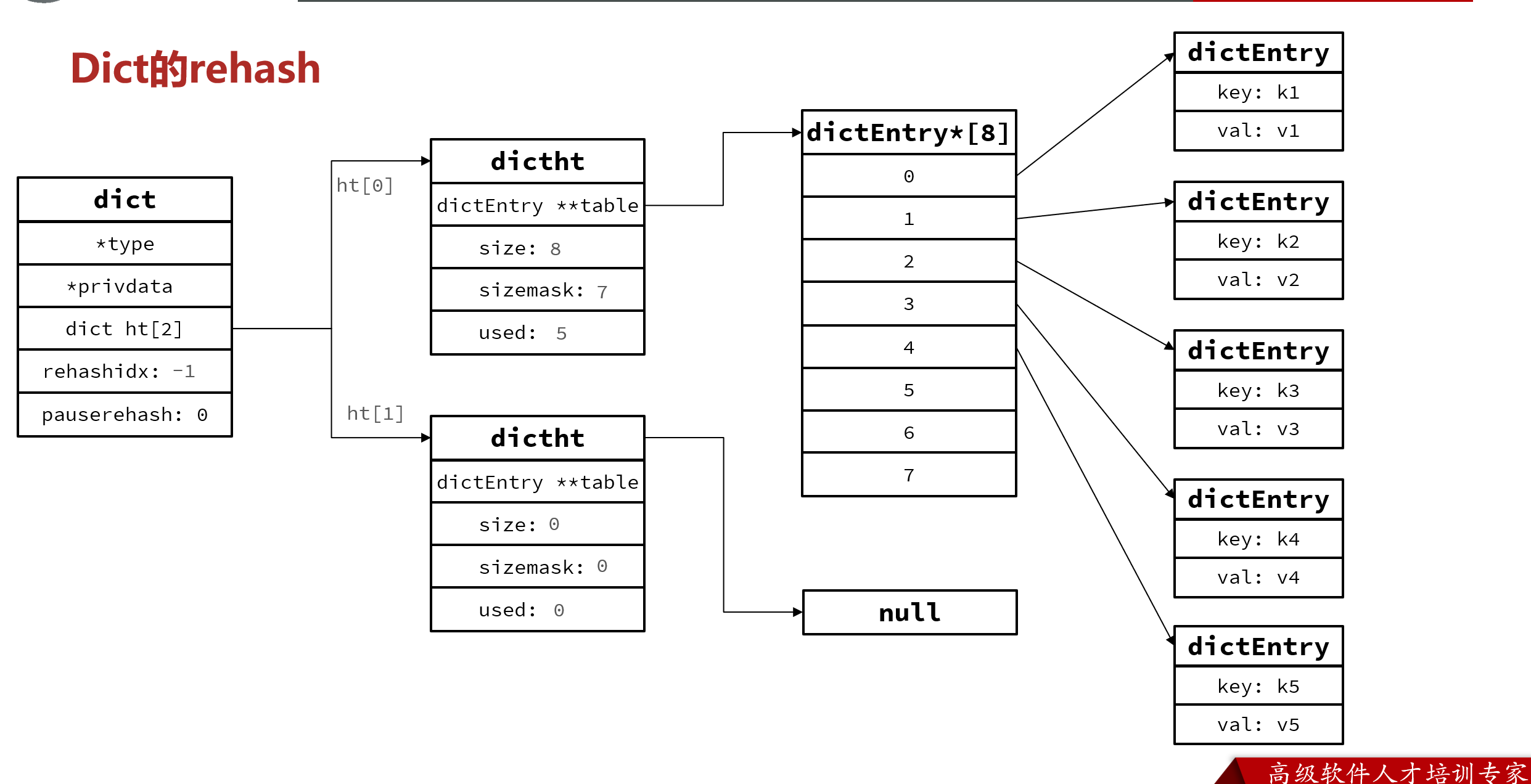
uDict采用渐进式rehash,每次访问Dict时执行一次rehash
urehash时ht[0]只减不增,新增操作只在ht[1]执行,其它操作在两个哈希表
ZipList
ZipList特性:
①压缩列表的可以看做一种连续内存空间的”双向链表”
②列表的节点之间不是通过指针连接,而是记录上一节点和本节点长度来寻址,内存占用较低
③如果列表数据过多,导致链表过长,可能影响查询性能
④增或删较大数据时有可能发生连续更新问题
QuickList
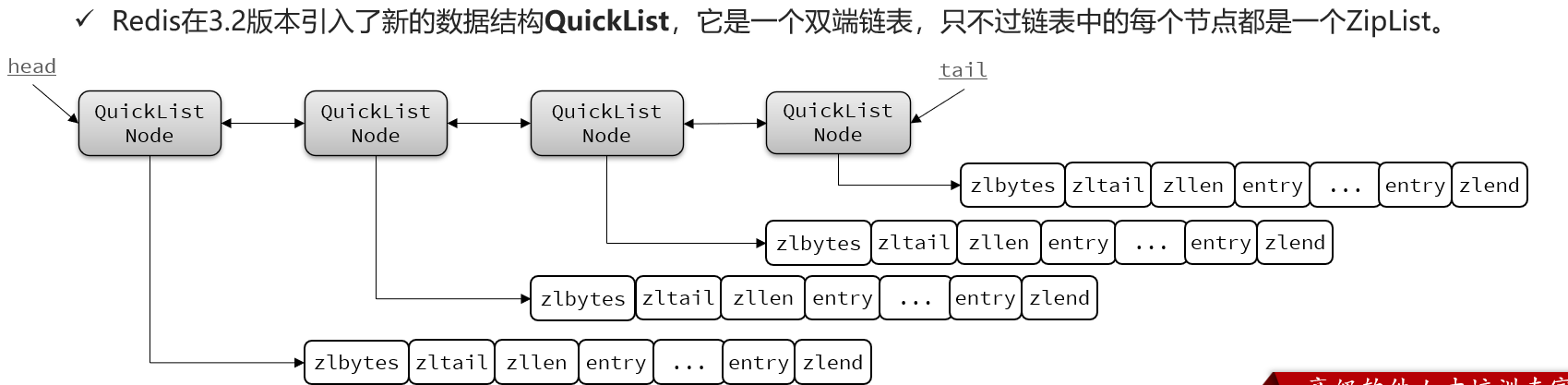
每个ZipList的内存占用不能超过8kb(可配置),控制ziplist占用内存的大小。
zipList的中间节点可以压缩,进一步节省了内存
SkipList

Redis五种数据结构

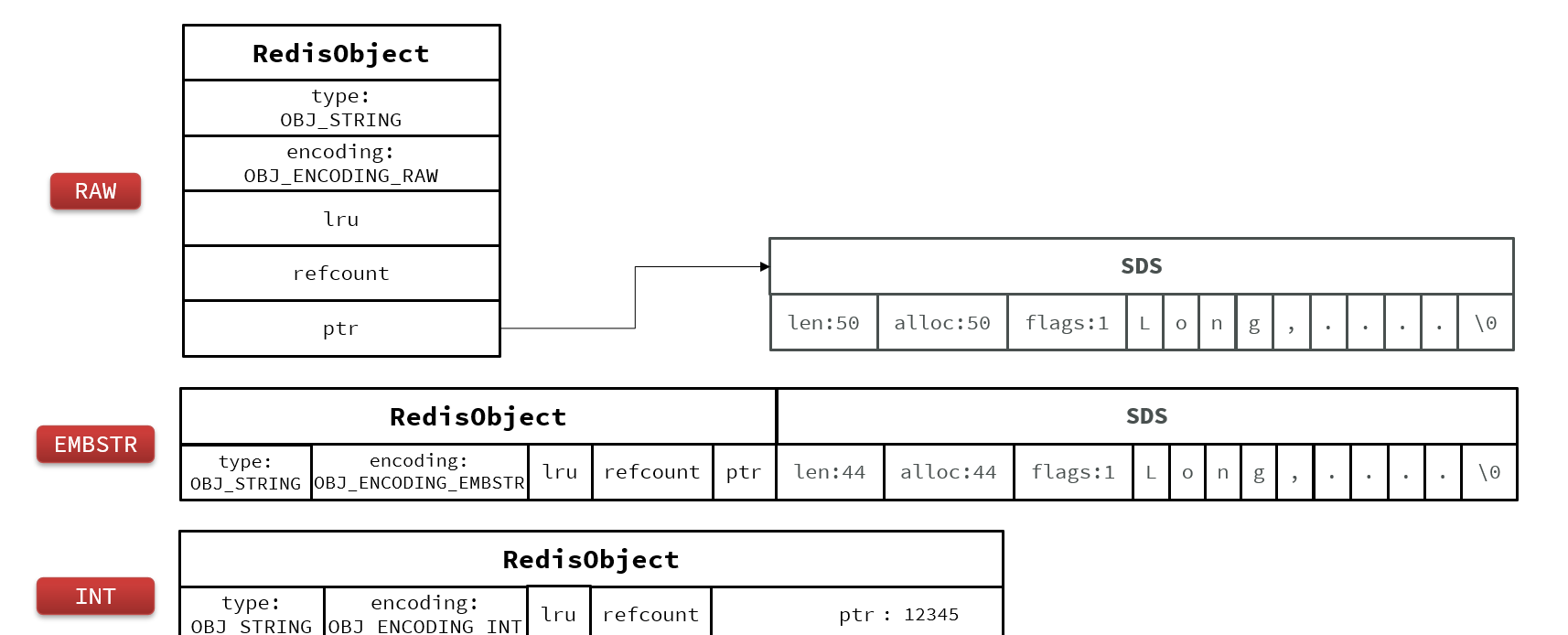
String
其基本编码方式是RAW,基于简单动态字符串(SDS)实现,存储上限为512mb。
如果存储的SDS长度小于44字节,则会采用EMBSTR编码,此时object head与SDS是一段连续空间。申请内存时只需要调用一次内存分配函数,效率更高。
如果存储的字符串是整数值,并且大小在LONG_MAX范围内,则会采用INT编码:直接将数据保存在RedisObject的ptr指针位置(刚好8字节),不再需要SDS了。
List
在3.2版本之前,Redis采用ZipList和LinkedList来实现List,当元素数量小于512并且元素大小小于64字节时采用ZipList编码,超过则采用LinkedList编码。
在3.2版本之后,采用QuickList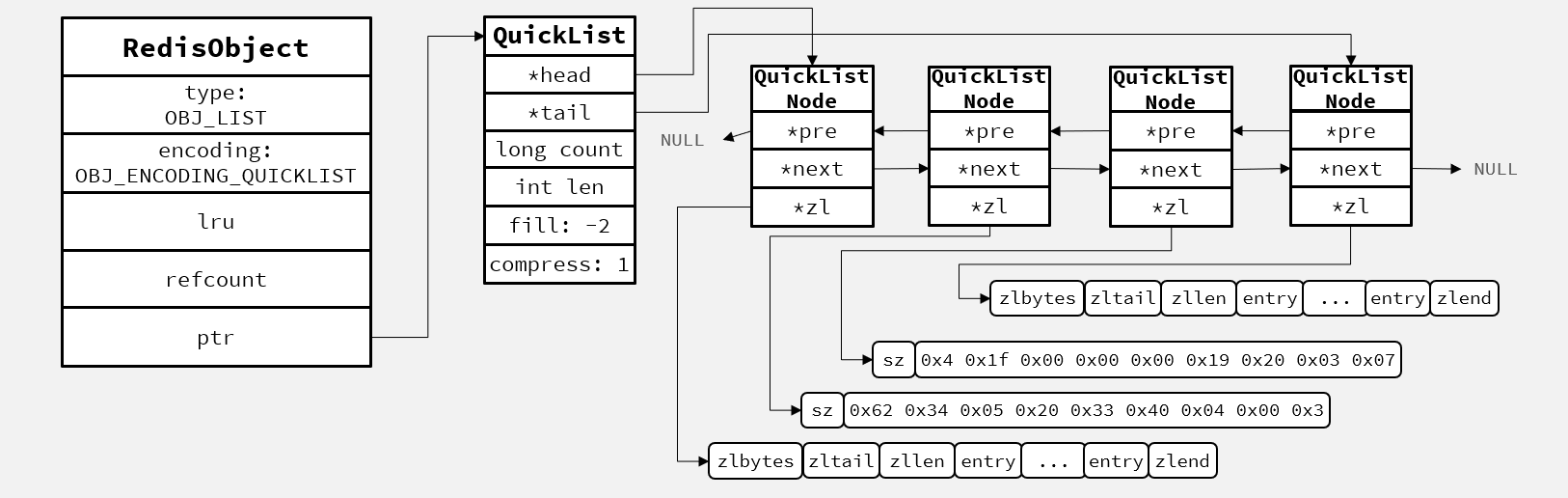
set
少量整数IntSet,正常采用Dict,元素存在key中,value为null
当添加一个字符串后,会从上面变成下面。
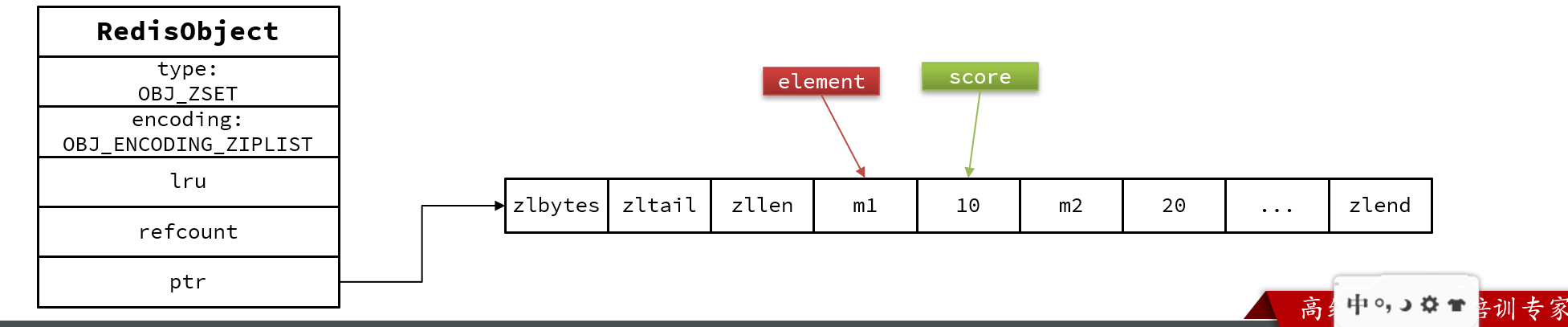
zset
zset底层数据结构必须满足键值存储、键必须唯一、可排序这几个需求。
SkipList:可以排序,并且可以同时存储score和ele值(member)
HashTable:可以键值存储,并且可以根据key找value
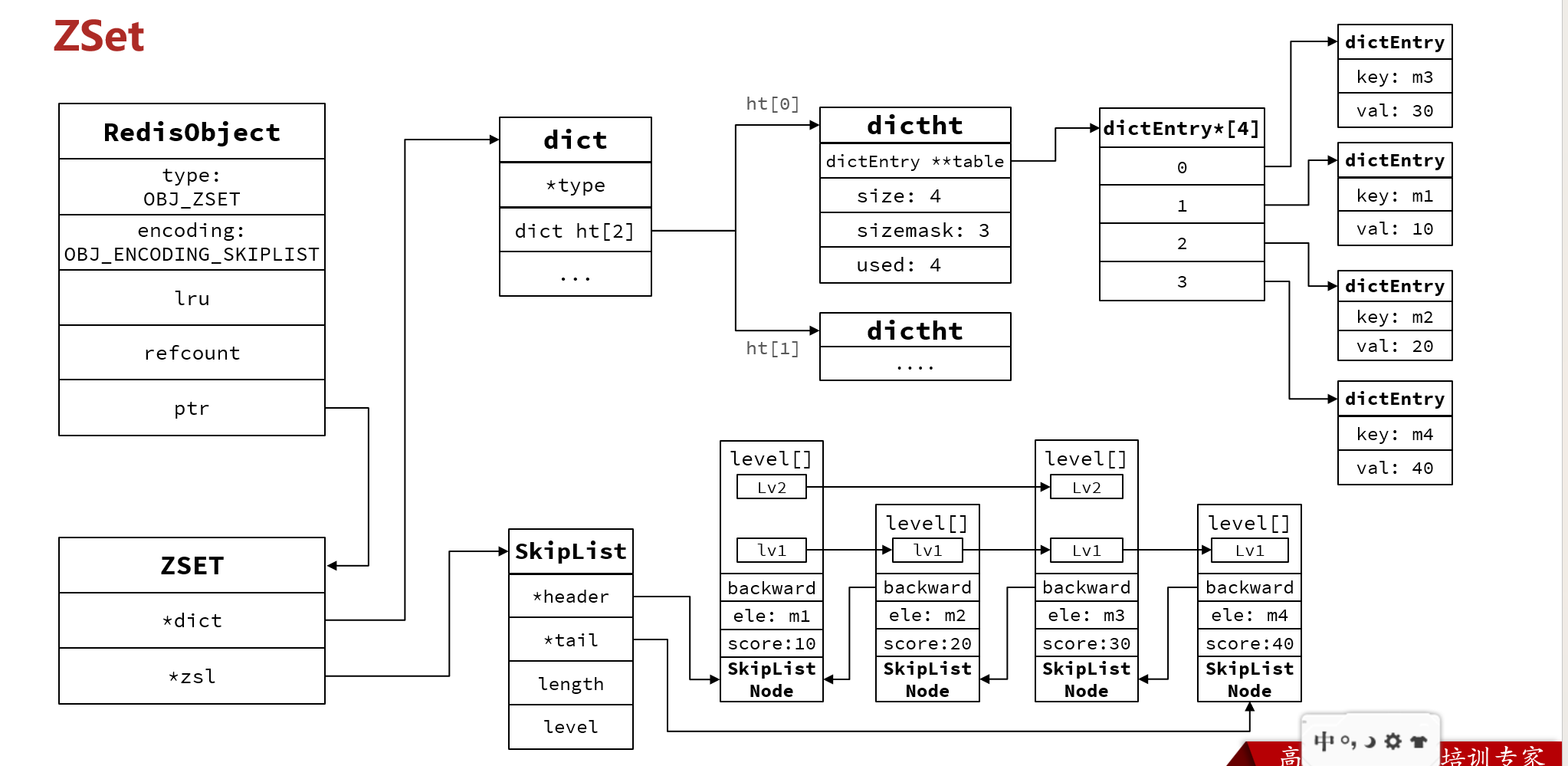
数据存了两份,太占用内存了。
当元素数量不多时,zset还会采用ZipList结构来节省内存,不过需要同时满足两个条件:
①元素数量小于zset_max_ziplist_entries,默认值128
②每个元素都小于zset_max_ziplist_value字节,默认值64
ziplist本身没有排序功能,而且没有键值对的概念,因此需要有zset通过编码实现:
- ZipList是连续内存,因此score和element是紧挨在一起的两个entry, element在前,score在后
- score越小越接近队首,score越大越接近队尾,按照score值升序排列
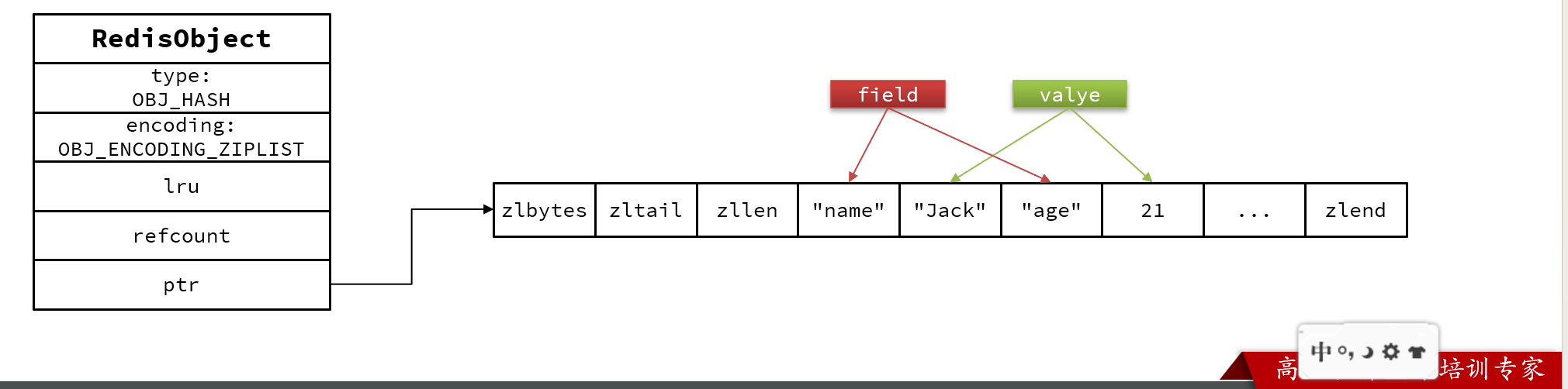
hash
少量数据ziplist,大量数据dict
Hash结构默认采用ZipList编码,用以节省内存。 ZipList中相邻的两个entry 分别保存field和value
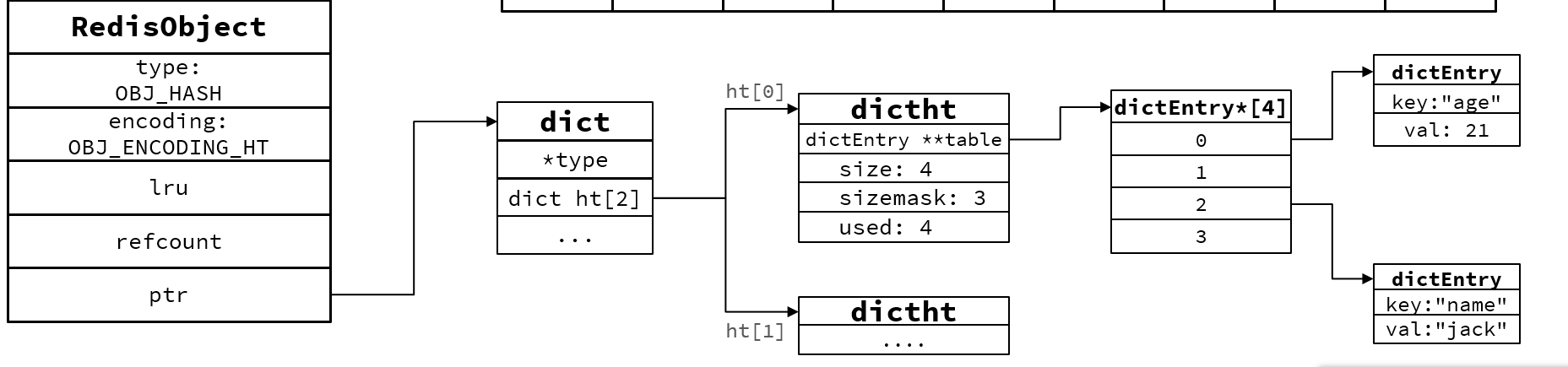
当数据量较大时,Hash结构会转为HT编码,也就是Dict,触发条件有两个:
- ZipList中的元素数量超过了hash-max-ziplist-entries(默认512)
- ZipList中的任意entry大小超过了hash-max-ziplist-value(默认64字节)
用户空间和内核空间
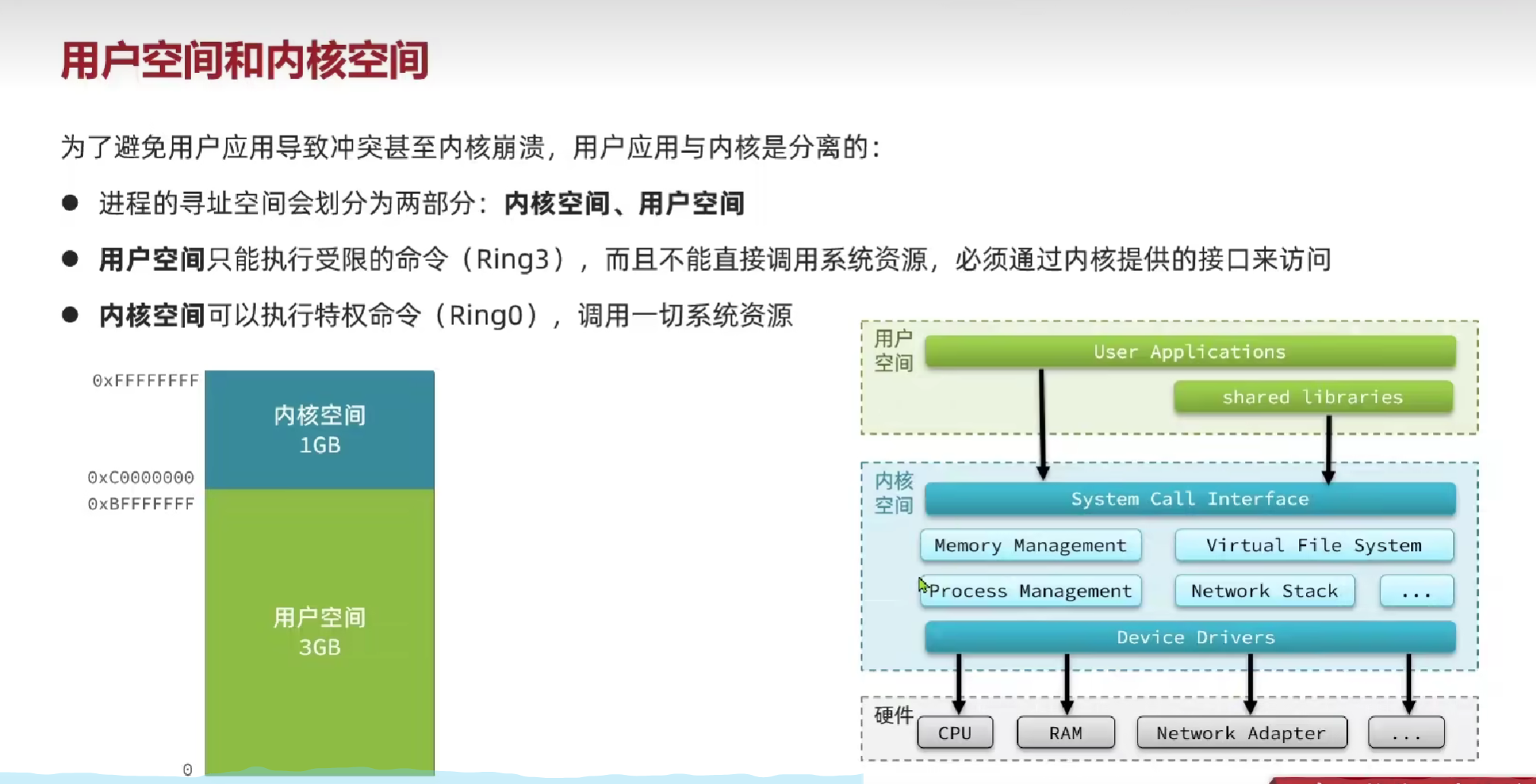
Linux系统为了提高IO效率,在用户空间和内核空间都加入了缓冲区。
写数据时,要把用户缓冲数据拷贝到内核缓冲区,然后写入设备。
读数据时,要从设备读取数据到内核缓冲区,然后拷贝到用户缓冲区。
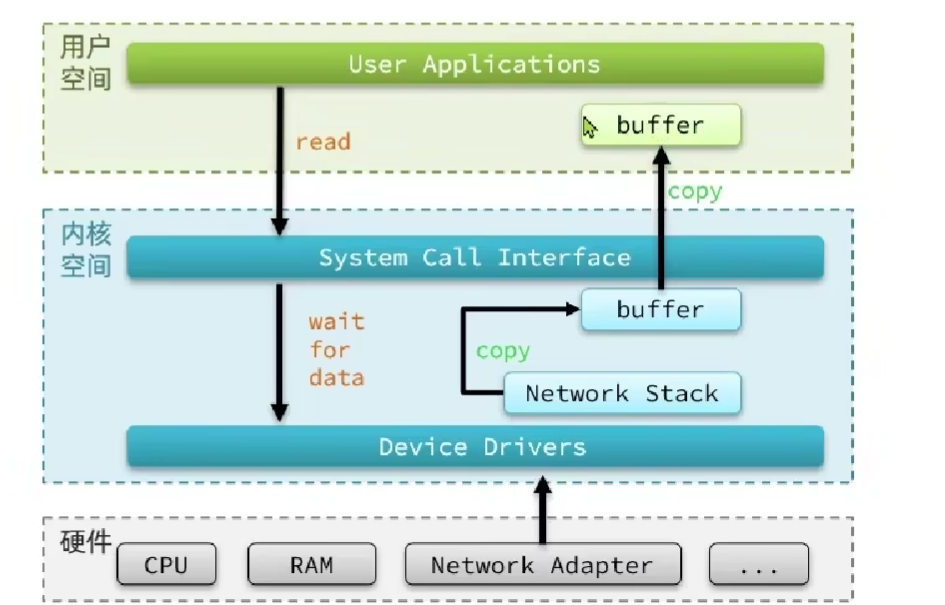
下面的5种IO,都是在解决两个点:1,内核空间中的等待 2,用户态和内核态的缓冲区之间的拷贝。
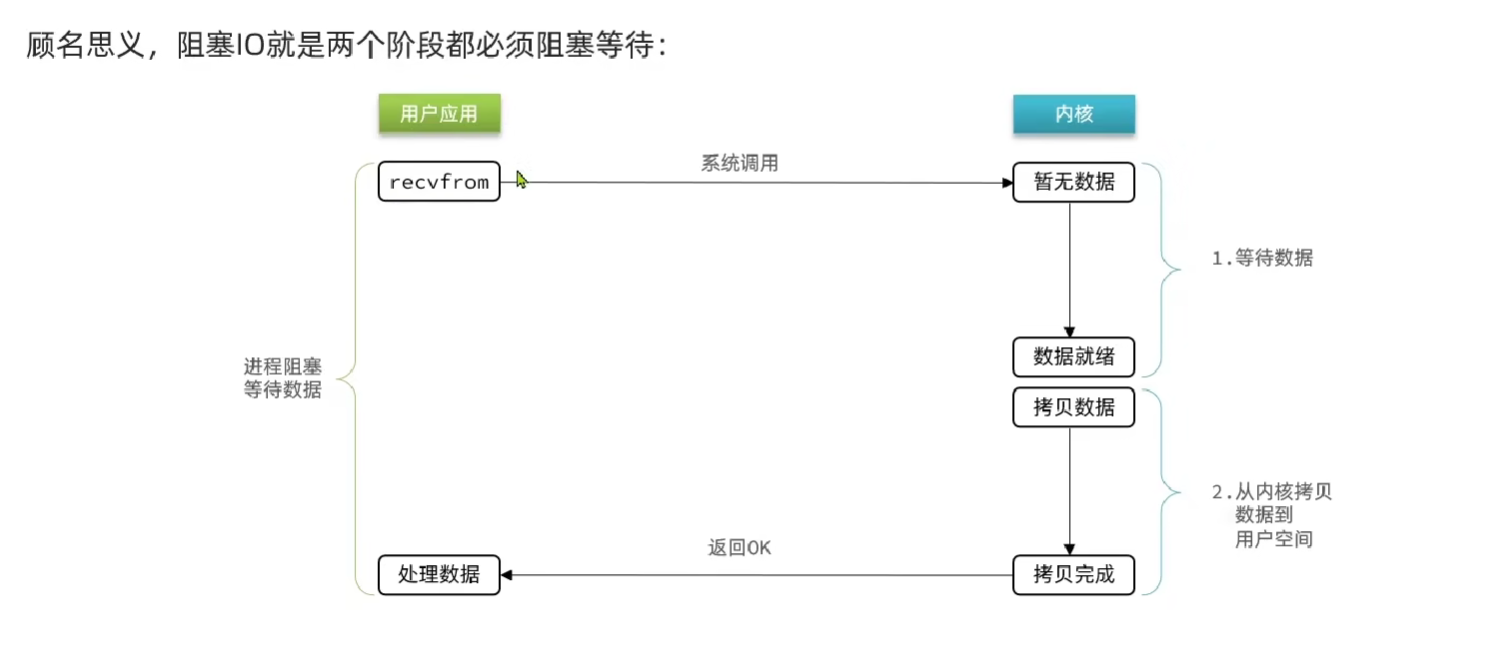
阻塞IO
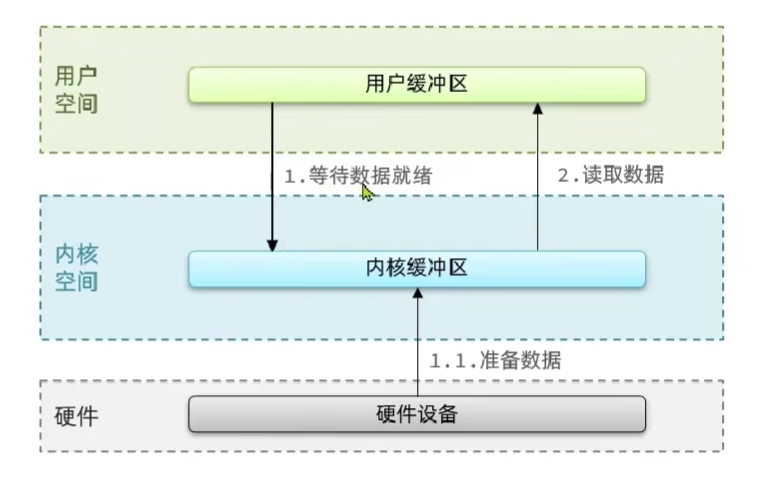
对于用户进程和内核进程:
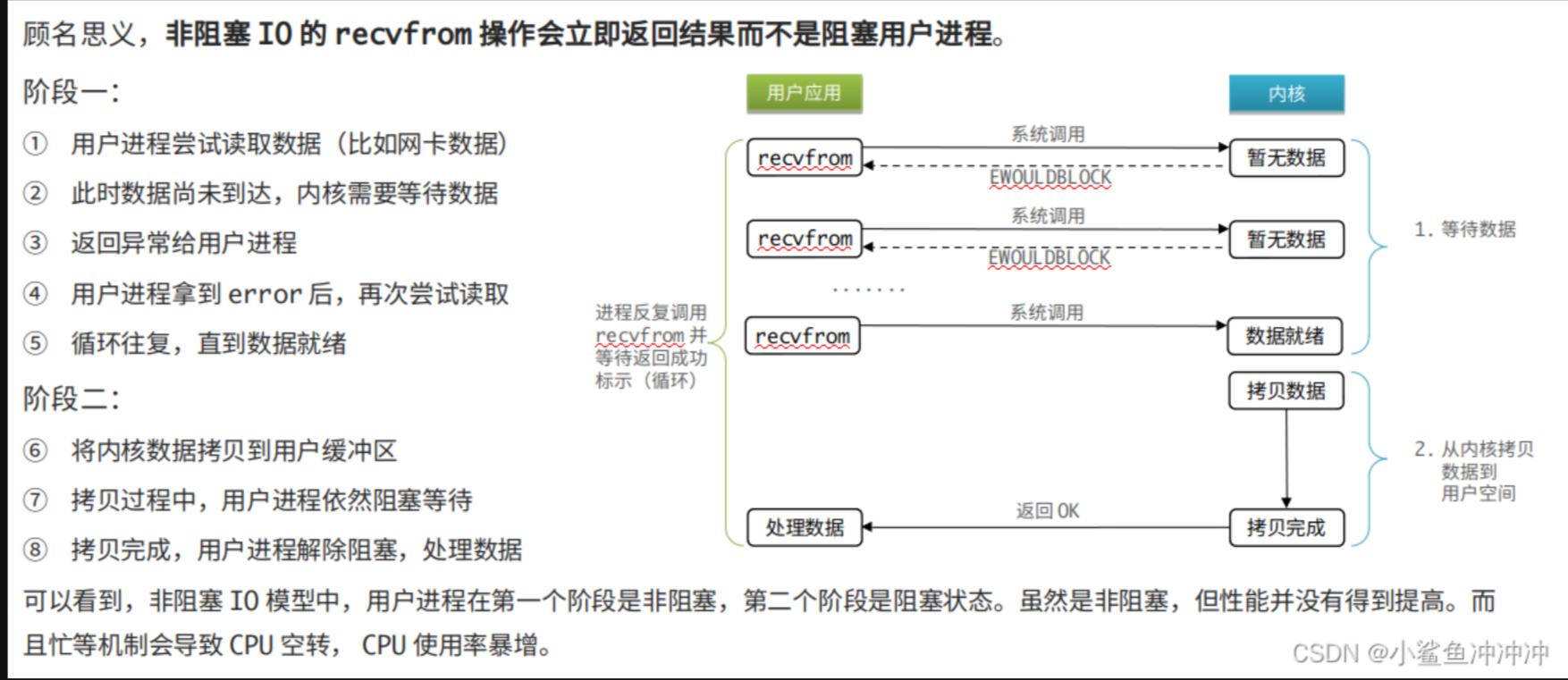
非阻塞IO
并没有提升性能,反而导致CPU使用率暴增。但是IO多路复用必须结合非阻塞IO才有足够好的性能表现。
IO多路复用
服务端处理客户端的socket请求时,在单线程情况下,只能依次处理每一个socket,如果正在处理的socket恰好未就绪(不可读或者不可写),线程就会被阻塞,所有其他客户端socket都必须等待,性能自然会很差。
单线程会导致处理业务阻塞。其他业务必须等着。
用户进程如何知道内核中数据是否就绪呢?
IO多路复用:利用单个线程来同时监听多个FD(文件描述符),并在某个FD可读,可写的时候通知,返回readable.应该是一个单独的后台线程去监听。
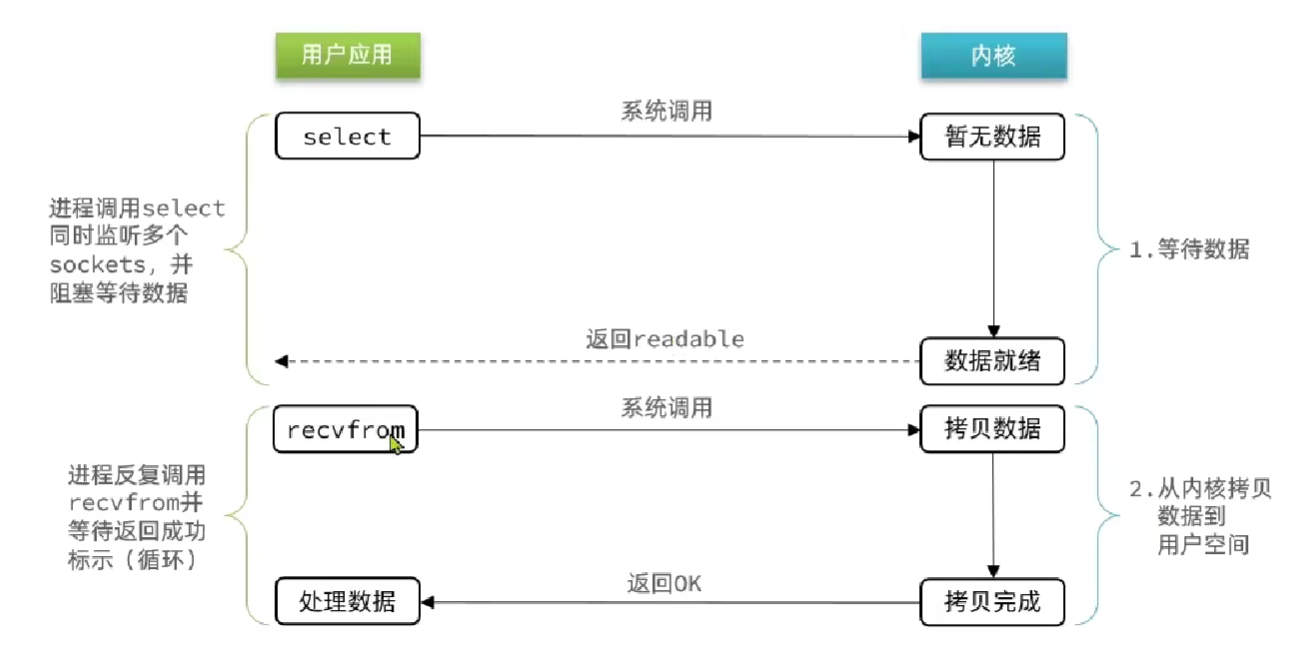
监听的方式有多种,select和poll只会通知有,不会告诉你是哪个,要用户一个个遍历。
epoll则同时也会告诉是哪个FD就绪了,并将其写入用户空间。

epoll中的事件通知机制
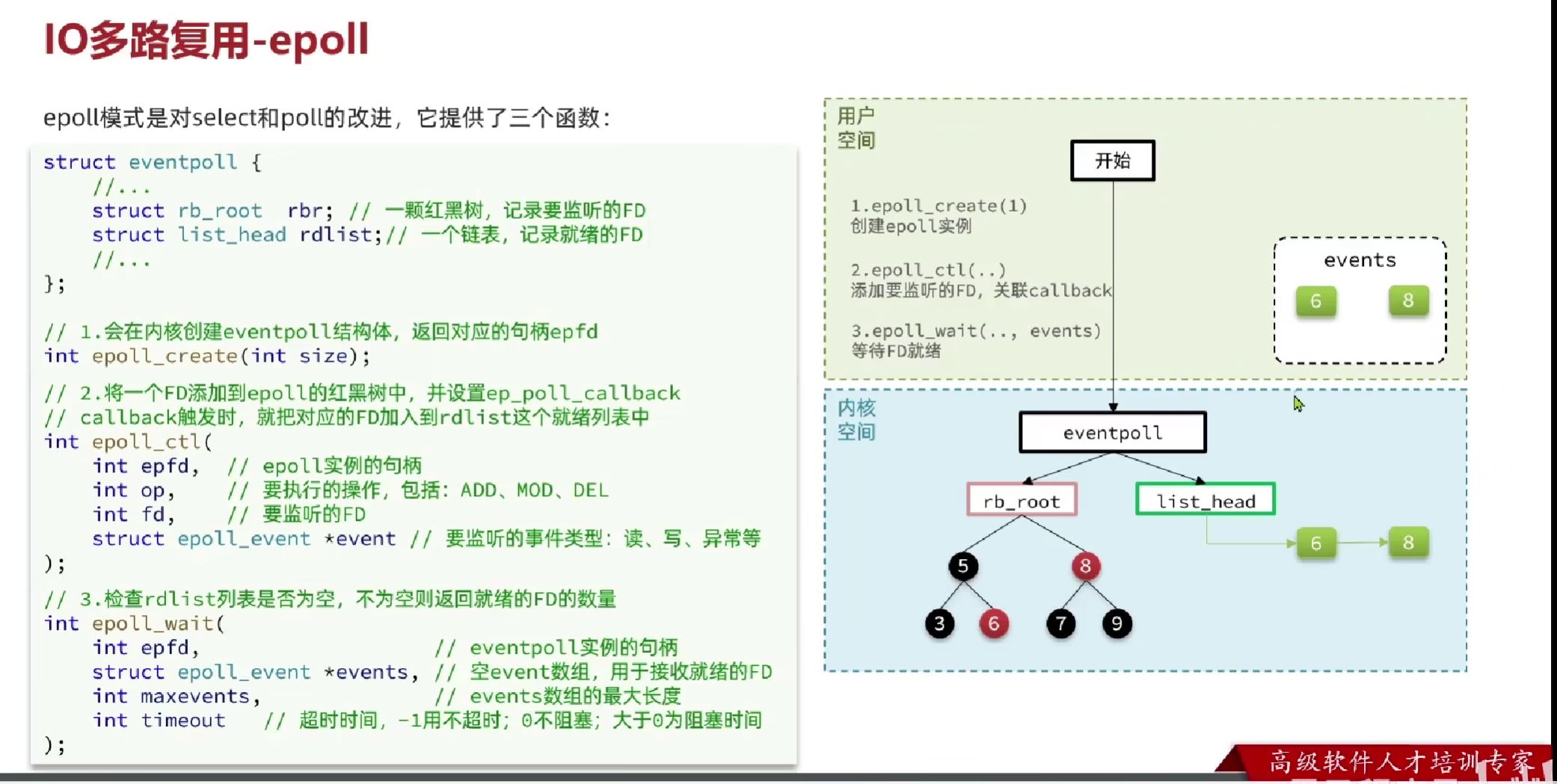

如果我们确实想用ET模式,可以在4之后调用epoll_ctl,让内核检查rb_root中是否有未被处理的,如果有则放到list_head中。也可以循环的执行4将数据读完(不要用阻塞IO的方式)。
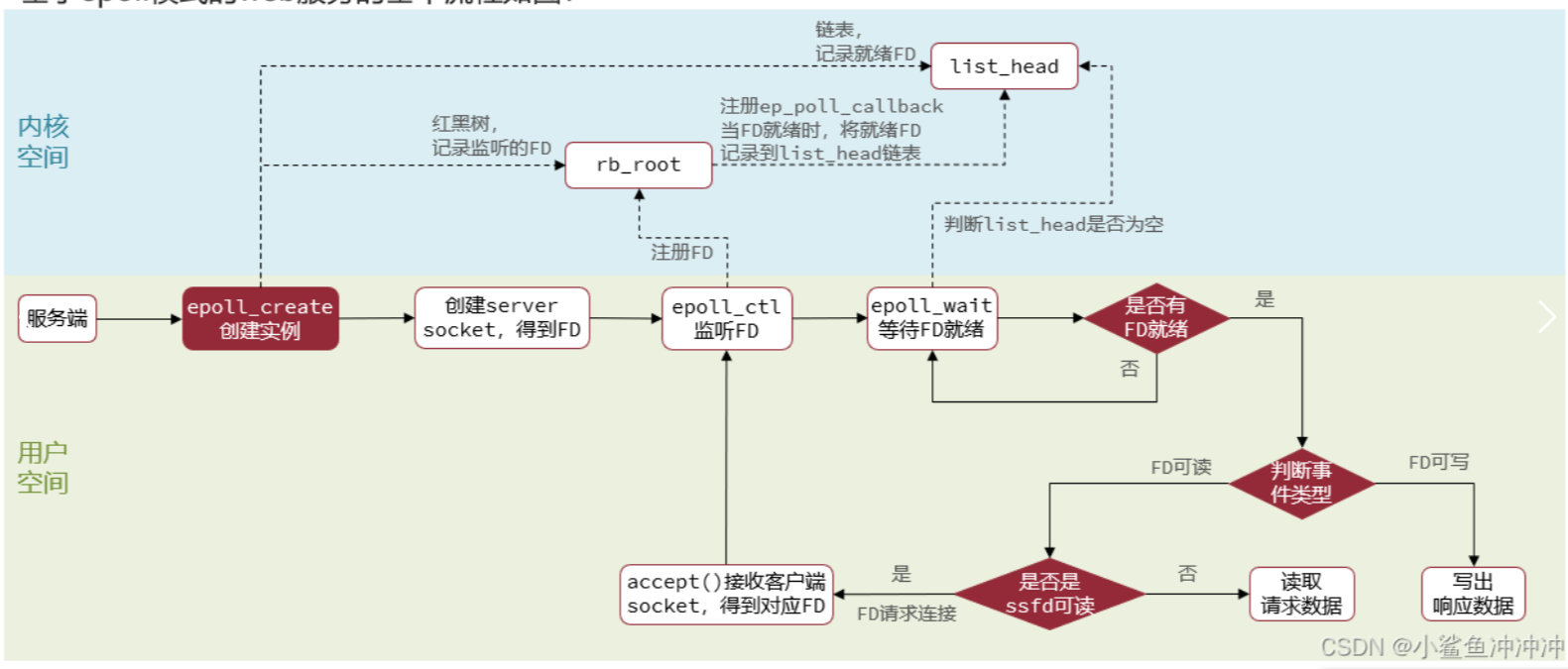
基于epoll模式的web服务的基本流程如图:
信号驱动IO
recvfrom函数–数据拷贝函数

异步IO
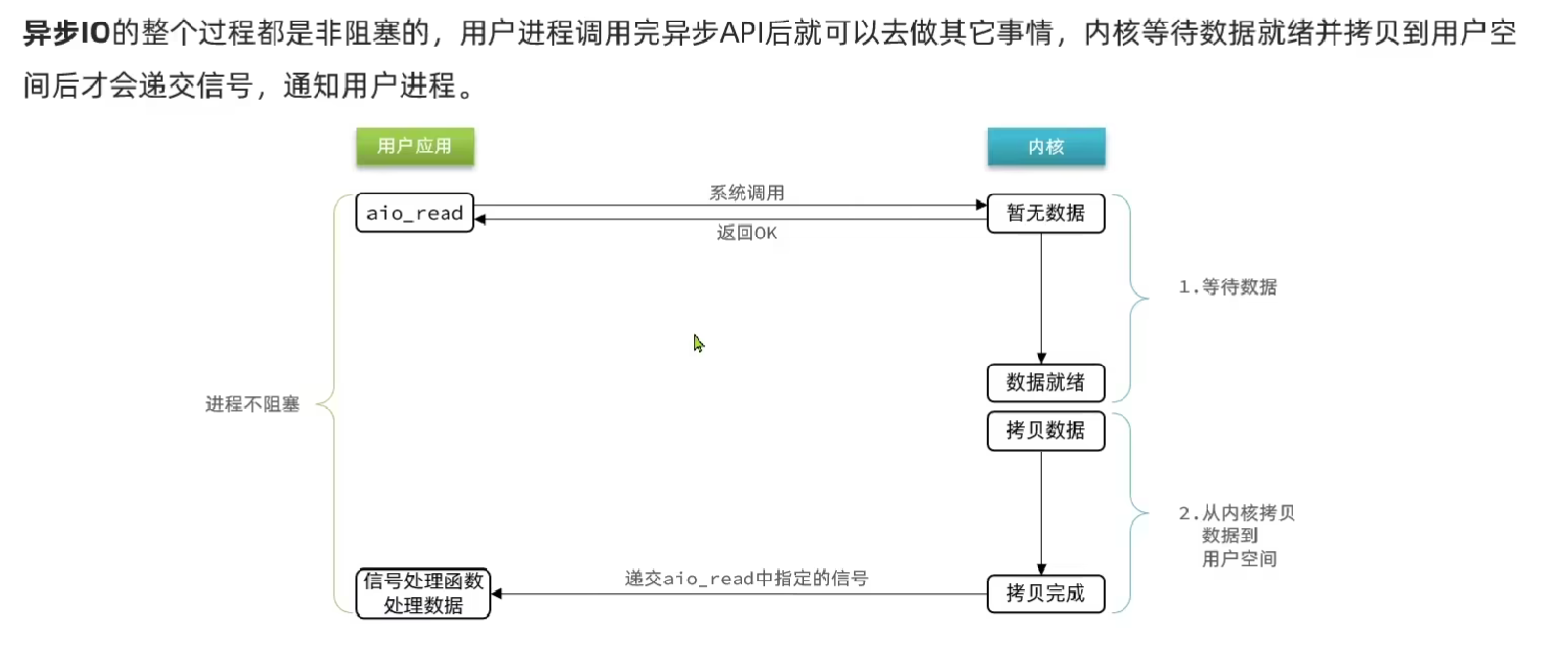
用户应用大量安排任务,可能导致整个系统内存占用过多而崩溃。
总结:

Redis网络模型
命令处理部分是单线程的,在Redis6.0版本中,核心网络模型加入了多线程。
Redis是纯内存操作,它的性能瓶颈是网络延迟而不是执行速度,多线程并不能带来巨大的性能提升。相反会导致过多的上下文切换,带来不必要的开销。
而且引入多线程会面临线程安全问题。加锁的话性能更差了。
过期策略
Redis 通过一个叫做过期字典(可以看作是 hash 表)来保存数据过期的时间。
惰性删除:不是在TTL到期后就立刻删除,而是在访问一个key的时候,检查该key的存活时间,如果已经过期才执行删除。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
定期删除:每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
定期删除中SLOW模式(服务器初始化的时候被定义),间隔长(100ms一次)每一次时间长(25模式)。FAST模式(每个事件循环前调用beforeSleep函数),间隔短(2ms)每一次也短(1ms)。
淘汰策略
就是当Redis内存使用达到设置的上限时,主动挑选部分key删除以释放更多内存的流程。
一刀切,只要来访问,都会看内存够不够。




