数据库基础
范式
- 第一范式:确保原子性,表中每一个列数据都必须是不可再分的字段。(如果某一列存的是JSON,则不满足1NF)
- 第二范式:确保唯一性,每张表都只描述一种业务属性,一张表只描述一件事。(第二范式在第一范式的基础上增加了一个列,这个列称为主键,非主属性都依赖于主键)
- 第三范式:确保独立性,表中除主键外,每个字段之间不存在任何依赖,都是独立的。(比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖,所以该表的设计,不符合 3NF 的要求。)
不推荐使用外键和级联
Ali开发手册:外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度。
增加了复杂性: a. 每次做 DELETE 或者 UPDATE 都必须考虑外键约束,会导致开发的时候很痛苦, 测试数据极为不方便; b. 外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
增加了额外工作:数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗资源;(个人觉得这个不是不用外键的原因,因为即使你不使用外键,你在应用层面也还是要保证的。所以,我觉得这个影响可以忽略不计。)
对分库分表不友好:因为分库分表下外键是无法生效的。
存储过程
我们可以把存储过程看成是一些 SQL 语句的集合,中间加了点逻辑控制语句。
存储过程一旦调试完成通过后就能稳定运行,另外,使用存储过程比单纯 SQL 语句执行要快,因为存储过程是预编译过的。
存储过程在互联网公司应用不多,因为存储过程难以调试和扩展,而且没有移植性,还会消耗数据库资源。
阿里巴巴 Java 开发手册里要求禁止使用存储过程。
删除操作
drop(丢弃数据): drop table 表名 ,直接将表都删除掉,在删除表的时候使用。
truncate (清空数据) : truncate table 表名 ,只删除表中的数据,再插入数据的时候自增长 id 又从 1 开始,在清空表中数据的时候使用。
delete(删除数据) : delete from 表名 where 列名=值,删除某一行的数据
NoSQL
文档:MongoDB、CouchDB,
键值:Redis、DynamoDB,
宽列: HBase、Cassandra,
图表:Neo4j、 Amazon Neptune、Giraph
字符集
**utf8**:utf8编码只支持1-3个字节 。 在 utf8 编码中,中文是占 3 个字节,其他数字、英文、符号占一个字节。但 emoji 符号占 4 个字节,一些较复杂的文字、繁体字也是 4 个字节。
**utf8mb4**:UTF-8 的完整实现,正版!最多支持使用 4 个字节表示字符,因此,可以用来存储 emoji 符号。
sql语法基础知识
SQL支持三种注释
两个# 注释1
– 注释2
/* 注释3 */
数据定义语言(Data Definition Language,DDL)的主要功能是定义数据库对象,其核心指令是create,alter,drop.
数据操纵语言(DML) 的主要功能是 访问数据,因此其语法都是以读写数据库为主。核心指令是CRUD,insert,update,delete,select
事务控制语言 (Transaction Control Language, TCL) 用于管理数据库中的事务.核心指令是commit,rollback
数据控制语言 (Data Control Language, DCL) 以控制用户的访问权限为主
插入:
INSERTINTOuserVALUES(10,’root’,’root’,‘xxxx@163.com‘),(12,’user1’,’user1’,‘xxxx@163.com‘),(18,’user2’,’user2’,‘xxxx@163.com‘);
INSERT INTO user(username, password, email)
VALUES (‘admin’, ‘admin’, ‘xxxx@163.com‘);
插入查询出来的数据:
INSERT INTO user(username)
SELECT name
FROM account;
更新:
UPDATE user
SET username=’robot’, password=’robot’
WHERE username = ‘root’;
删除:
DELETE FROM user
WHERE username = ‘robot’;
查询:
DISTINCT 用于返回唯一不同的值。它作用于所有列,也就是说所有列的值都相同才算相同。
LIMIT 限制返回的行数。可以有两个参数,第一个参数为起始行,从 0 开始;第二个参数为返回的总行数
having用于对汇总的group by结果进行过滤。
SELECT cust_name, COUNT(*) AS num
FROM Customers
WHERE cust_email IS NOT NULL
GROUP BY cust_name
HAVING COUNT(*) >= 1;
join连接两张表。
如果两张表的关联字段名相同,也可以使用 USING子句来代替 ON,举个例子
# join....on
select c.cust_name, o.order_num
from Customers c
inner join Orders o
on c.cust_id = o.cust_id
order by c.cust_name;
# 如果两张表的关联字段名相同,也可以使用USING子句:join....using()
select c.cust_name, o.order_num
from Customers c
inner join Orders o
using(cust_id)
order by c.cust_name;
各种不同的连接。
| 连接类型 | 说明 |
|---|---|
| INNER JOIN 内连接 | (默认连接方式)只有当两个表都存在满足条件的记录时才会返回行。 |
| LEFT JOIN / LEFT OUTER JOIN 左(外)连接 | 返回左表中的所有行,即使右表中没有满足条件的行也是如此。 |
| RIGHT JOIN / RIGHT OUTER JOIN 右(外)连接 | 返回右表中的所有行,即使左表中没有满足条件的行也是如此。 |
| FULL JOIN / FULL OUTER JOIN 全(外)连接 | 只要其中有一个表存在满足条件的记录,就返回行。 |
| SELF JOIN | 将一个表连接到自身,就像该表是两个表一样。为了区分两个表,在 SQL 语句中需要至少重命名一个表。 |
| CROSS JOIN | 交叉连接,从两个或者多个连接表中返回记录集的笛卡尔积。 |
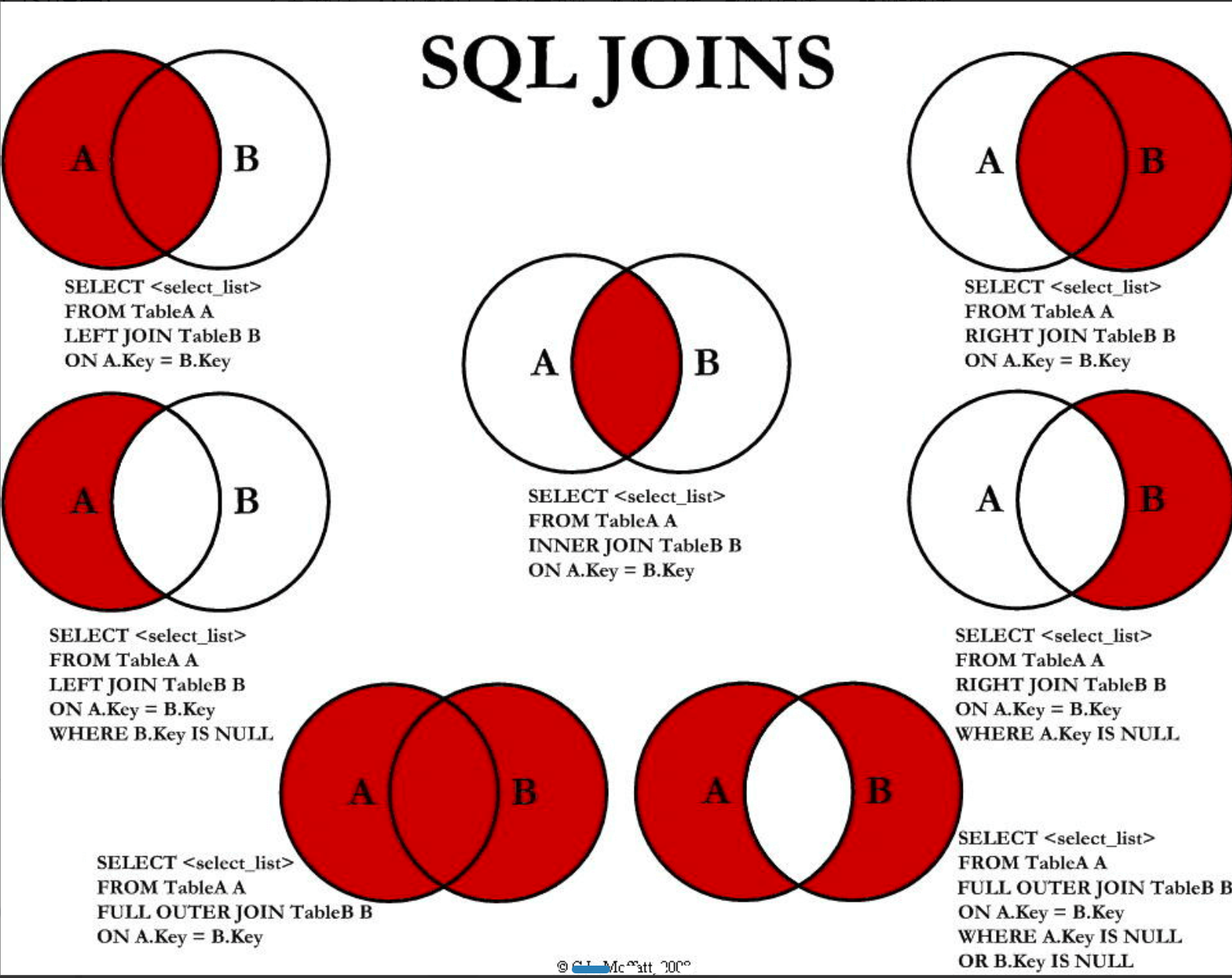
UNION 基本规则:
- 所有查询的列数和列顺序必须相同。
- 每个查询中涉及表的列的数据类型必须相同或兼容。
- 通常返回的列名取自第一个查询。
默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
SELECT column_name(s) FROM table1
UNION ALL
SELECT column_name(s) FROM table2;
文本处理
| 函数 | 说明 |
|---|---|
LEFT()、RIGHT() |
左边或者右边的字符 |
LOWER()、UPPER() |
转换为小写或者大写 |
LTRIM()、RTRIM() |
去除左边或者右边的空格 |
| LENGTH() | 长度,以字节为单位 |
| SOUNDEX() | 转换为语音值 |
sql常见面试题
从 OrderItems 表中检索出所有不同且不重复的订单号(order_num),其中每个订单都要包含 100 个或更多的产品。
SELECT order_num
FROM OrderItems
GROUP BY order_num
HAVING SUM(quantity) >= 100
在 SQL 中,可使用以下通配符:
| 通配符 | 描述 |
|---|---|
| % | 代表零个或多个字符 |
| _ | 仅替代一个字符 |
| [charlist] | 字符列中的任何单一字符 |
[^charlist]或者[!charlist] |
不在字符列中的任何单一字符 |
仅返回描述中未出现 toy 一词的产品 WHERE prod_desc NOT LIKE ‘%toy%’
SELECT cust_id, cust_name, UPPER(CONCAT(SUBSTRING(cust_contact, 1, 2),SUBSTRING(cust_city, 1, 3))) AS user_login
FROM Customers
截取函数SUBSTRING():截取字符串,substring(str ,n ,m)(n 表示起始截取位置,m 表示要截取的字符个数)表示返回字符串 str 从第 n 个字符开始截取 m 个字符;
拼接函数CONCAT():将两个或多个字符串连接成一个字符串,select concat(A,B):连接字符串 A 和 B。
大写函数 UPPER():将指定字符串转换为大写。
返回 2020 年 1 月的所有订单的订单号 WHERE month(order_date) = ‘01’ AND YEAR(order_date) = ‘2020’ 或者是 WHERE order_date LIKE ‘2020-01%’
编写 SQL 语句,返回每个订单号(order_num)各有多少行数(order_lines),并按 order_lines 对结果进行升序排序。
SELECT order_num, Count(order_num) AS order_lines
FROM OrderItems
GROUP BY order_num
ORDER BY order_lines
知识点:
count(*),count(列名)都可以,区别在于,count(列名)是统计非 NULL 的行数;order by最后执行,所以可以使用列别名;- 分组聚合一定不要忘记加上
group by,不然只会有一行结果。
编写 SQL 语句,返回名为 cheapest_item 的字段,该字段包含每个供应商(vend_id)成本最低的产品(使用 Products 表中的 prod_price),然后从最低成本到最高成本对结果进行升序排序。
SELECT vend_id, Min(prod_price) AS cheapest_item
FROM Products
GROUP BY vend_id
ORDER BY cheapest_item
子查询,连接表。
如果两张表的关联字段名相同,也可以使用 USING子句来代替 ON
SELECT cust_email
FROM Customers
INNER JOIN Orders using(cust_id)
INNER JOIN OrderItems using(order_num)
WHERE OrderItems.prod_id = 'BR01'
group by 的应该是select 里除了聚和函数之外的所有值。 having的是聚和函数的结果
SELECT cust_name, SUM(item_price * quantity) AS total_price
FROM Customers
INNER JOIN Orders USING(cust_id)
INNER JOIN OrderItems USING(order_num)
GROUP BY cust_name
HAVING total_price >= 1000
ORDER BY total_price
使用 union 组合查询时,只能使用一条 order by 字句,他必须位于最后一条 select 语句之后
默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
- 带更新的插入 :
REPLACE INTO table_name VALUES (value1, value2, ...)(注意这种原理是检测到主键或唯一性索引键重复就删除原记录后重新插入)
对于日期比较
UPDATE exam_record SET submit_time = '2099-01-01 00:00:00', score = 0
WHERE DATE(start_time) < "2021-09-01" AND submit_time IS null
要把日期封装到DATE里,再比较。
对于替换字段:
UPDATE examination_info SET tag = 'Python' WHERE tag='PYTHON'
UPDATE examination_info SET tag = REPLACE(tag,'PYTHON','Python')
可以直接set ,where . 也可以set的时候用replace字段
计算时间差,小于5分钟的删掉。
DELETE FROM exam_record WHERE MINUTE (TIMEDIFF(submit_time , start_time)) < 5
DELETE FROM exam_record WHERE TIMESTAMPDIFF(MINUTE, start_time, submit_time) < 5
我只删除最早的三条记录
delete from exam_order order by start_time limit 3
DROP: 清空表,删除表结构,不可逆TRUNCATE: 格式化表,不删除表结构,不可逆DELETE:删除数据,可逆
TRUNCATE会清空表中的所有行,但表结构及其约束、索引等保持不变;TRUNCATE会重置表的自增值;使用TRUNCATE后会使表和索引所占用的空间会恢复到初始大小。
MYSQL 的 ROUND() 函数 ,ROUND(X)返回参数 X 最近似的整数 ROUND(X,D)返回 X ,其值保留到小数点后 D 位,第 D 位的保留方式为四舍五入。
- 结合
GROUP BY使用,计算分组后每个组的行数:
SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name;
2计算不同列组合的唯一组合数:
SELECT COUNT(DISTINCT column_name1, column_name2) FROM table_name;
在使用 COUNT() 函数时,如果不指定任何参数或者使用 COUNT(*),将会计算所有行的数量。而如果使用列名,则只会计算该列非空值的数量。
另外,COUNT() 函数的结果是一个整数值。即使结果是零,也不会返回 NULL,这点需要谨记。
count的条件计数:
count(release_year = ‘2006’ or NULL)
因为如果年份不是2006,则结果为False也会参与计数, 故要添加 or NULL
SELECT COUNT( DISTINCT exam_id, score IS NOT NULL OR NULL ) FROM exam_record
下面这个sql非常长,可以用来学习顺序,limit在最后面。
SELECT a.uid,
SUM(CASE
WHEN a.submit_time IS NULL THEN 1
END) AS incomplete_cnt,
SUM(CASE
WHEN a.submit_time IS NOT NULL THEN 1
END) AS complete_cnt,
GROUP_CONCAT(DISTINCT CONCAT(DATE_FORMAT(a.start_time, '%Y-%m-%d'), ':', b.tag)
ORDER BY start_time SEPARATOR ";") AS detail
FROM exam_record a
LEFT JOIN examination_info b ON a.exam_id = b.exam_id
WHERE YEAR (a.start_time)= 2021
GROUP BY a.uid
HAVING incomplete_cnt > 1
AND complete_cnt >= 1
AND incomplete_cnt < 5
ORDER BY incomplete_cnt DESC
使用union和多个order by不加括号,报错!直接报语法错误,如果没有括号,只能有一个order by
解决办法就是加括号:
SELECT *
FROM
(SELECT exam_id AS tid,
COUNT(DISTINCT exam_record.uid) uv,
COUNT(*) pv
FROM exam_record
GROUP BY exam_id
ORDER BY uv DESC, pv DESC) t1
UNION
SELECT *
FROM
(SELECT question_id AS tid,
COUNT(DISTINCT practice_record.uid) uv,
COUNT(*) pv
FROM practice_record
GROUP BY question_id
ORDER BY uv DESC, pv DESC) t2;
窗口函数
窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。
窗口函数的基本语法如下:
<窗口函数> over (partition by <用于分组的列名>
order by <用于排序的列名>)
<窗口函数>的位置,可以放以下两种函数:
1) 专用窗口函数,比如rank, dense_rank, row_number等
2) 聚合函数,如sum. avg, count, max, min等
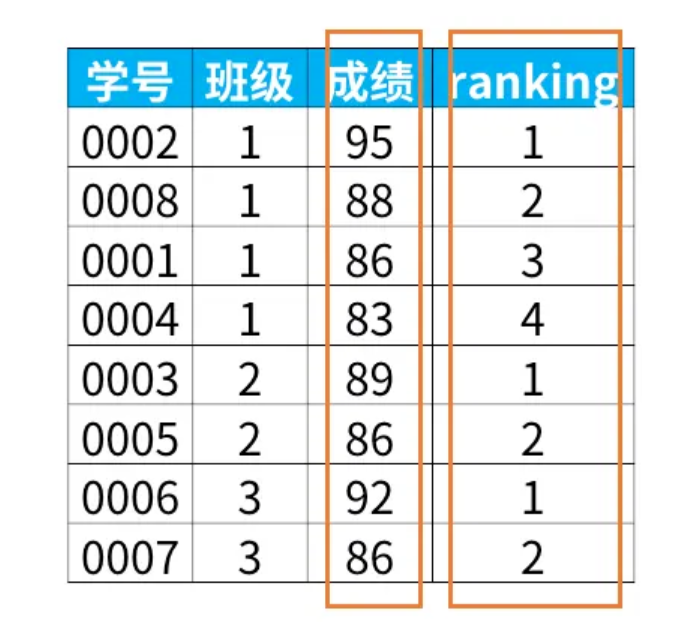
select *,
rank() over (partition by 班级
order by 成绩 desc) as ranking
from 班级表
IF可以作为一个三目运算符,当然用case when也可以
IF (er.submit_time IS NOT NULL, TIMESTAMPDIFF(MINUTE, start_time, submit_time), ef.duration) AS time_diff,
IF (er.submit_time IS NOT NULL,er.score,0) AS new_socre
文本转换函数
SUBSTRING_INDEX 函数用于提取字符串中指定分隔符的部分。它接受三个参数:原始字符串、分隔符和指定要返回的部分的数量。
以下是 SUBSTRING_INDEX 函数的语法:
SUBSTRING_INDEX(str, delimiter, count)
str:要进行分割的原始字符串。delimiter:用作分割的字符串或字符。count:指定要返回的部分的数量。
- 如果
count大于 0,则返回从左边开始的前count个部分(以分隔符为界)。 - 如果
count小于 0,则返回从右边开始的前count个部分(以分隔符为界),即从右侧向左计数。
- 如果
下面是一些示例,演示了 SUBSTRING_INDEX 函数的使用:
提取字符串中的第一个部分:
SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', 1);
-- 输出结果:'apple'
提取字符串中的最后一个部分:
SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', -1);
-- 输出结果:'cherry'
提取字符串中的前两个部分:
SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', 2);
-- 输出结果:'apple,banana'
提取字符串中的最后两个部分:
SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', -2);
-- 输出结果:'banana,cherry'
要计算字符串的字符数(即字符串的长度),可以使用 LENGTH 函数或 CHAR_LENGTH 函数。这两个函数的区别在于对待多字节字符的方式。
LENGTH函数:它返回给定字符串的字节数。对于包含多字节字符的字符串,每个字符都会被当作一个字节来计算。
示例:
SELECT LENGTH('你好'); -- 输出结果:6,因为 '你好' 中的每个汉字每个占3个字节
CHAR_LENGTH函数:它返回给定字符串的字符数。对于包含多字节字符的字符串,每个字符会被当作一个字符来计算。
示例:
SELECT CHAR_LENGTH('你好'); -- 输出结果:2,因为 '你好' 中有两个字符,即两个汉字
大小写转换函数:
1.UPPER(s)或UCASE(s)函数可以将字符串 s 中的字母字符全部转换成大写字母;
2.LOWER(s)或者LCASE(s)函数可以将字符串 s 中的字母字符全部转换成小写字母。
with A as (select * from class)
select *from A
对于大批量的数据,可以先暂存到A表中。



