JavaGuide自学记录1-Java基础与集合
浮点数之间的等值判断,基本数据类型不能用 == 来比较,包装数据类型不能用 equals 来判断。
BigDeecimal构建的时候,如果是double,推荐使用valueof
推荐使用它的BigDecimal(String val)构造方法或者 BigDecimal.valueOf(double val) 静态方法来创建对象。

BigDecimalUtil工具类
import java.math.BigDecimal;
import java.math.RoundingMode;
/**
* 简化BigDecimal计算的小工具类
*/
public class BigDecimalUtil {
/**
* 默认除法运算精度
*/
private static final int DEF_DIV_SCALE = 10;
private BigDecimalUtil() {
}
/**
* 提供精确的加法运算。
*
* @param v1 被加数
* @param v2 加数
* @return 两个参数的和
*/
public static double add(double v1, double v2) {
BigDecimal b1 = BigDecimal.valueOf(v1);
BigDecimal b2 = BigDecimal.valueOf(v2);
return b1.add(b2).doubleValue();
}
/**
* 提供精确的减法运算。
*
* @param v1 被减数
* @param v2 减数
* @return 两个参数的差
*/
public static double subtract(double v1, double v2) {
BigDecimal b1 = BigDecimal.valueOf(v1);
BigDecimal b2 = BigDecimal.valueOf(v2);
return b1.subtract(b2).doubleValue();
}
/**
* 提供精确的乘法运算。
*
* @param v1 被乘数
* @param v2 乘数
* @return 两个参数的积
*/
public static double multiply(double v1, double v2) {
BigDecimal b1 = BigDecimal.valueOf(v1);
BigDecimal b2 = BigDecimal.valueOf(v2);
return b1.multiply(b2).doubleValue();
}
/**
* 提供(相对)精确的除法运算,当发生除不尽的情况时,精确到
* 小数点以后10位,以后的数字四舍五入。
*
* @param v1 被除数
* @param v2 除数
* @return 两个参数的商
*/
public static double divide(double v1, double v2) {
return divide(v1, v2, DEF_DIV_SCALE);
}
/**
* 提供(相对)精确的除法运算。当发生除不尽的情况时,由scale参数指
* 定精度,以后的数字四舍五入。
*
* @param v1 被除数
* @param v2 除数
* @param scale 表示表示需要精确到小数点以后几位。
* @return 两个参数的商
*/
public static double divide(double v1, double v2, int scale) {
if (scale < 0) {
throw new IllegalArgumentException(
"The scale must be a positive integer or zero");
}
BigDecimal b1 = BigDecimal.valueOf(v1);
BigDecimal b2 = BigDecimal.valueOf(v2);
return b1.divide(b2, scale, RoundingMode.HALF_EVEN).doubleValue();
}
/**
* 提供精确的小数位四舍五入处理。
*
* @param v 需要四舍五入的数字
* @param scale 小数点后保留几位
* @return 四舍五入后的结果
*/
public static double round(double v, int scale) {
if (scale < 0) {
throw new IllegalArgumentException(
"The scale must be a positive integer or zero");
}
BigDecimal b = BigDecimal.valueOf(v);
BigDecimal one = new BigDecimal("1");
return b.divide(one, scale, RoundingMode.HALF_UP).doubleValue();
}
/**
* 提供精确的类型转换(Float)
*
* @param v 需要被转换的数字
* @return 返回转换结果
*/
public static float convertToFloat(double v) {
BigDecimal b = new BigDecimal(v);
return b.floatValue();
}
/**
* 提供精确的类型转换(Int)不进行四舍五入
*
* @param v 需要被转换的数字
* @return 返回转换结果
*/
public static int convertsToInt(double v) {
BigDecimal b = new BigDecimal(v);
return b.intValue();
}
/**
* 提供精确的类型转换(Long)
*
* @param v 需要被转换的数字
* @return 返回转换结果
*/
public static long convertsToLong(double v) {
BigDecimal b = new BigDecimal(v);
return b.longValue();
}
/**
* 返回两个数中大的一个值
*
* @param v1 需要被对比的第一个数
* @param v2 需要被对比的第二个数
* @return 返回两个数中大的一个值
*/
public static double returnMax(double v1, double v2) {
BigDecimal b1 = new BigDecimal(v1);
BigDecimal b2 = new BigDecimal(v2);
return b1.max(b2).doubleValue();
}
/**
* 返回两个数中小的一个值
*
* @param v1 需要被对比的第一个数
* @param v2 需要被对比的第二个数
* @return 返回两个数中小的一个值
*/
public static double returnMin(double v1, double v2) {
BigDecimal b1 = new BigDecimal(v1);
BigDecimal b2 = new BigDecimal(v2);
return b1.min(b2).doubleValue();
}
/**
* 精确对比两个数字
*
* @param v1 需要被对比的第一个数
* @param v2 需要被对比的第二个数
* @return 如果两个数一样则返回0,如果第一个数比第二个数大则返回1,反之返回-1
*/
public static int compareTo(double v1, double v2) {
BigDecimal b1 = BigDecimal.valueOf(v1);
BigDecimal b2 = BigDecimal.valueOf(v2);
return b1.compareTo(b2);
}
}
语法糖-自动拆装箱
先来看个自动装箱的代码:
public static void main(String[] args) {
int i = 10;
Integer n = i;
}
反编译后代码如下:
public static void main(String args[])
{
int i = 10;
Integer n = Integer.valueOf(i);
}
再来看个自动拆箱的代码:
public static void main(String[] args) {
Integer i = 10;
int n = i;
}
反编译后代码如下:
public static void main(String args[])
{
Integer i = Integer.valueOf(10);
int n = i.intValue();
}
从反编译得到内容可以看出,在装箱的时候自动调用的是Integer的valueOf(int)方法。而在拆箱的时候自动调用的是Integer的intValue方法。
所以,装箱过程是通过调用包装器的 valueOf 方法实现的,而拆箱过程是通过调用包装器的 xxxValue 方法实现的
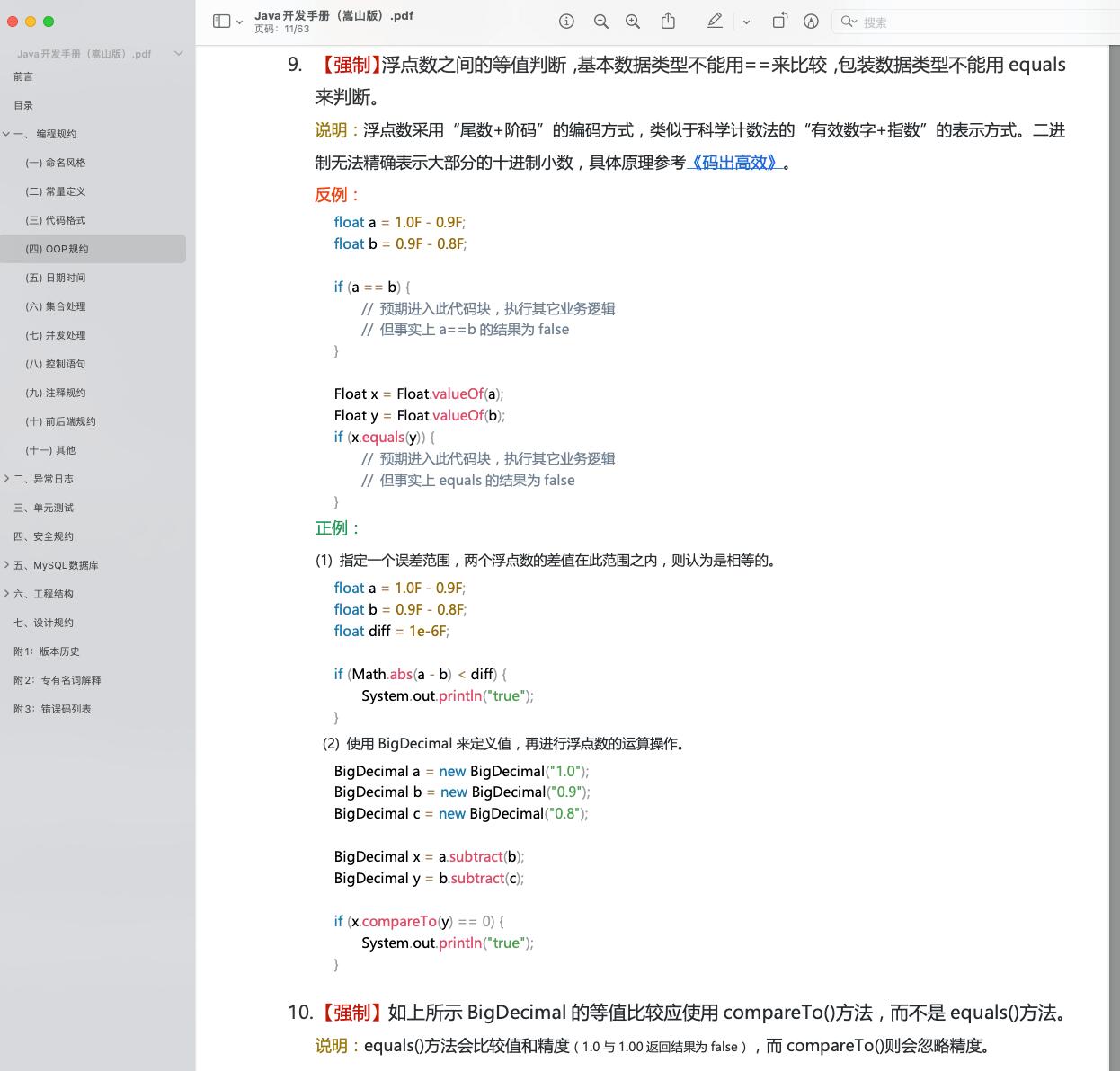
集合类继承关系
Comparable和Comparator区别
内部的和外部的实现一个即可。
内部的:Comparable 接口实际上是出自java.lang包 它有一个 compareTo(Object obj)方法用来排序
外部的:Comparator接口实际上是出自 java.util 包它有一个compare(Object obj1, Object obj2)方法用来排序
内部的要在类内重写compareTo方法
public class Person implements Comparable<Person> {
String name;
int age;
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public Person() {
super();
}
@Override
public int compareTo(Person o) {
return this.age - o.age;
}
}
然后直接Arrays.sort(persons)就行
外部的要实现一个比较类,推荐使用匿名内部类
Arrays.sort(list, new Comparator<Person>() {
@Override
public int compare(Person o1,Person o2) {
return o1.getAge()- o2.getAge();
}
});
Collections.sort(arrayList, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});
TreeMap的排序使用
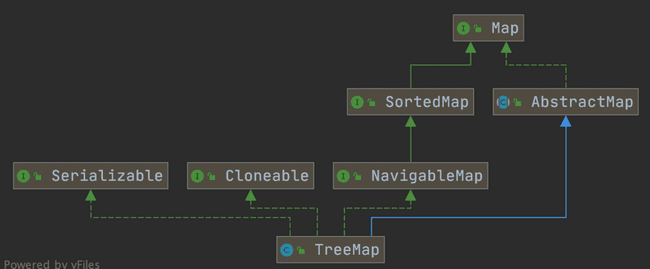
实现 NavigableMap 接口让 TreeMap 有了对集合内元素的搜索的能力。
实现SortedMap接口让 TreeMap 有了对集合中的元素根据键排序的能力。默认是按 key 的升序排序,不过我们也可以指定排序的比较器。示例代码如下
/**
* @author shuang.kou
* @createTime 2020年06月15日 17:02:00
*/
public class Person {
private Integer age;
public Person(Integer age) {
this.age = age;
}
public Integer getAge() {
return age;
}
public static void main(String[] args) {
TreeMap<Person, String> treeMap = new TreeMap<>(new Comparator<Person>() {
@Override
public int compare(Person person1, Person person2) {
int num = person1.getAge() - person2.getAge();
return Integer.compare(num, 0);
}
});
treeMap.put(new Person(3), "person1");
treeMap.put(new Person(18), "person2");
treeMap.put(new Person(35), "person3");
treeMap.put(new Person(16), "person4");
treeMap.entrySet().stream().forEach(personStringEntry -> {
System.out.println(personStringEntry.getValue());
});
}
}
上面,我们是通过传入匿名内部类的方式实现的,你可以将代码替换成 Lambda 表达式实现的方式
TreeMap<Person, String> treeMap = new TreeMap<>((person1, person2) -> {
int num = person1.getAge() - person2.getAge();
return Integer.compare(num, 0);
});
hashmap的遍历方式
首先,用迭代器或者foreach, 他们的性能都是相同的,因为他们最终生成的字节码基本都是一样的。
EntrySet 的性能比 KeySet 的性能高出了一倍,因为 KeySet 相当于循环了两遍 Map 集合,而 EntrySet 只循环了一遍。
因为如果你用keyset的话,你使用**map.get(key) 查询时**,也会再遍历一遍map,所以相当于遍历了两遍。
遍历(不删除)
// 遍历-迭代器
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
// 遍历-foreach
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
// 遍历-lambda表达式
map.forEach((key, value) -> {
System.out.println(key);
System.out.println(value);
});
// 遍历-streamAPI-单线程
map.entrySet().stream().forEach((entry) -> {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
});
// 遍历-streamAPI-多线程
map.entrySet().parallelStream().forEach((entry) -> {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
});
遍历(循环删除)
对于普通的foreach的循环删除,会报错
for (Map.Entry<Integer, String> entry : map.entrySet()) {
if (entry.getKey() == 1) {
// 删除
System.out.println("del:" + entry.getKey());
map.remove(entry.getKey());
} else {
System.out.println("show:" + entry.getKey());
}
}

从报错中可以看出,HashMap$HashIterator.nextNode这个方法有代码错误了,点进去看,大概知道HashMap.this.modCount != this.expectedModCount 成立
再看一下hashmap的remove操作是做了什么:
这里对modCount进行了自增操作,表示操作动作+1。再看modCount和expectedModCount是什么东西
可以看出迭代器初始化的时候就对modCount和expectedModCount进行同步。
到此,可以看出报错的原因:
hashmap里维护了一个modCount变量,迭代器里维护了一个expectedModCount变量,一开始两者是一样的。
每次进行hashmap.remove操作的时候就会对modCount+1,此时迭代器里的expectedModCount还是之前的值。
在下一次对迭代器进行next()调用时,判断是否HashMap.this.modCount != this.expectedModCount,如果是则抛出异常。
那什么情况下在遍历的时候可以删除map里面的元素呢?可以使用迭代器提供的remove方法
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
if (entry.getKey() == 1) {
// 删除
System.out.println("del:" + entry.getKey());
iterator.remove();
} else {
System.out.println("show:" + entry.getKey());
}
}
// lambda表达式--根据 map 中的 key 去判断删除
map.keySet().removeIf(key -> key == 1);
map.forEach((key, value) -> {
System.out.println("show:" + key);
});
先使用 Lambda 的 removeIf 删除多余的数据,再进行循环是一种正确操作集合的方式。
map.entrySet().stream().filter(m -> 1 != m.getKey()).forEach((entry) -> {
if (entry.getKey() == 1) {
System.out.println("del:" + entry.getKey());
} else {
System.out.println("show:" + entry.getKey());
}
});
可以使用 Stream 中的 filter 过滤掉无用的数据,再进行遍历也是一种安全的操作集合的方式。
综合性能和安全性来看,我们应该尽量使用迭代器(Iterator)来遍历 EntrySet 的遍历方式来操作 Map 集合,这样就会既安全又高效了。
如何保证 ConcurrentHashMap 复合操作的原子性呢?
ConcurrentHashMap 提供了一些原子性的复合操作,如 putIfAbsent、compute、computeIfAbsent 、computeIfPresent、merge等。这些方法都可以接受一个函数作为参数,根据给定的 key 和 value 来计算一个新的 value,并且将其更新到 map 中
Collections 工具类常用方法–排序,查找/替换
void reverse(List list)//反转
void shuffle(List list)//随机排序
void sort(List list)//按自然排序的升序排序
void sort(List list, Comparator c)//定制排序,由Comparator控制排序逻辑
void swap(List list, int i , int j)//交换两个索引位置的元素
void rotate(List list, int distance)//旋转。当distance为正数时,将list后distance个元素整体移到前面。当distance为负数时,将 list的前distance个元素整体移到后面
int binarySearch(List list, Object key)//对List进行二分查找,返回索引,注意List必须是有序的
int max(Collection coll)//根据元素的自然顺序,返回最大的元素。 类比int min(Collection coll)
int max(Collection coll, Comparator c)//根据定制排序,返回最大元素,排序规则由Comparatator类控制。类比int min(Collection coll, Comparator c)
void fill(List list, Object obj)//用指定的元素代替指定list中的所有元素
int frequency(Collection c, Object o)//统计元素出现次数
int indexOfSubList(List list, List target)//统计target在list中第一次出现的索引,找不到则返回-1,类比int lastIndexOfSubList(List source, list target)
boolean replaceAll(List list, Object oldVal, Object newVal)//用新元素替换旧元素
虽然里面的参数是List,但是List是个很大的接口。Collection下面分为Set,List,Queue三个接口,List的范围之广可见一斑。
集合判空-isEmpty()
判断所有集合内部的元素是否为空,使用
isEmpty()方法,而不是size()==0的方式。
集合转map
在使用
java.util.stream.Collectors类的toMap()方法转为Map集合时,一定要注意当 value 为 null 时会抛 NPE 异常。
class Person {
private String name;
private String phoneNumber;
// getters and setters
}
List<Person> bookList = new ArrayList<>();
bookList.add(new Person("jack","18163138123"));
bookList.add(new Person("martin",null));
// 空指针异常
bookList.stream().collect(Collectors.toMap(Person::getName, Person::getPhoneNumber));
集合遍历
不要在 foreach 循环里进行元素的
remove/add操作。remove 元素请使用Iterator方式,如果并发操作,需要对Iterator对象加锁。
通过反编译你会发现 foreach 语法底层其实还是依赖 Iterator 。不过, remove/add 操作直接调用的是集合自己的方法,而不是 Iterator 的 remove/add方法
这就导致 Iterator 莫名其妙地发现自己有元素被 remove/add ,然后,它就会抛出一个 ConcurrentModificationException 来提示用户发生了并发修改异常。这就是单线程状态下产生的 fail-fast 机制。
Java8 开始,可以使用 Collection#removeIf()方法删除满足特定条件的元素,如
List<Integer> list = new ArrayList<>();
for (int i = 1; i <= 10; ++i) {
list.add(i);
}
list.removeIf(filter -> filter % 2 == 0); /* 删除list中的所有偶数 */
System.out.println(list); /* [1, 3, 5, 7, 9] */
fail-fast 机制:多个线程对 fail-fast 集合进行修改的时候,可能会抛出ConcurrentModificationException。 即使是单线程下也有可能会出现这种情况.
java.util包下面的所有的集合类都是 fail-fast 的,而java.util.concurrent包下面的所有的类都是 fail-safe 的。
集合去重
可以利用
Set元素唯一的特性,可以快速对一个集合进行去重操作,避免使用List的contains()进行遍历去重或者判断包含操作。
集合转数组
使用集合转数组的方法,必须使用集合的
toArray(T[] array),传入的是类型完全一致、长度为 0 的空数组
String [] s= new String[]{
"dog", "lazy", "a", "over", "jumps", "fox", "brown", "quick", "A"
};
List<String> list = Arrays.asList(s);
Collections.reverse(list);
//没有指定类型的话会报错 java: 不兼容的类型: java.lang.Object[]无法转换为java.lang.String[]
s=list.toArray(new String[0]);
for (String s1 : s) {
System.out.println(s1); //可以顺利的倒序输出
}
数组转集合
使用工具类
Arrays.asList()把数组转换成集合时,不能使用其修改集合相关的方法, 它的add/remove/clear方法会抛出UnsupportedOperationException异常。
String[] myArray = {"Apple", "Banana", "Orange"};
List<String> myList = Arrays.asList(myArray);
//上面两个语句等价于下面一条语句
// List<String> myList = Arrays.asList("Apple","Banana", "Orange");
System.out.println(myList); // [Apple, Banana, Orange]
System.out.println(myList.get(0)); //Apple
String是包装类型,Integer也是包装的,但是int[]是基础类型
Arrays.asList()是泛型方法,传递的数组必须是对象数组,而不是基本类型
int[] myArray = {1, 2, 3};
List myList = Arrays.asList(myArray);
System.out.println(myList.size());//1
System.out.println(myList.get(0));//数组地址值
System.out.println(myList.get(1));//报错:ArrayIndexOutOfBoundsException
int[] array = (int[]) myList.get(0);
System.out.println(array[0]);//1
下面也会报错
List<Integer> myList = Arrays.asList(1, 2, 3);
myList.add(4);//运行时报错:UnsupportedOperationException
myList.remove(1);//运行时报错:UnsupportedOperationException
myList.clear();//运行时报错:UnsupportedOperationException
Arrays.asList() 方法返回的并不是 java.util.ArrayList ,而是 java.util.Arrays 的一个内部类,这个内部类并没有实现集合的修改方法或者说并没有重写这些方法。
那我们如何正确的将数组转换为 ArrayList ?
1.手动实现工具类
//JDK1.5+
static <T> List<T> arrayToList(final T[] array) {
final List<T> l = new ArrayList<T>(array.length);
for (final T s : array) {
l.add(s);
}
return l;
}
Integer [] myArray = { 1, 2, 3 };
System.out.println(arrayToList(myArray).getClass());//class java.util.ArrayList
2.最简便的办法
List list = new ArrayList<>(Arrays.asList("a", "b", "c"))
3.使用Java8的Stream(推荐)
Integer [] myArray = { 1, 2, 3 };
List myList = Arrays.stream(myArray).collect(Collectors.toList());
//基本类型也可以实现转换(依赖boxed的装箱操作)
int [] myArray2 = { 1, 2, 3 };
List myList = Arrays.stream(myArray2).boxed().collect(Collectors.toList());
4.使用Guava
对于不可变集合,你可以使用类ImmutableList及其of()与copyOf()工厂方法:(参数不能为空)
List<String> il = ImmutableList.of("string", "elements"); // from varargs
List<String> il = ImmutableList.copyOf(aStringArray); // from array
对于可变集合,你可以使用Lists类及其newArrayList()工厂方法:
List<String> l1 = Lists.newArrayList(anotherListOrCollection); // from collection
List<String> l2 = Lists.newArrayList(aStringArray); // from array
List<String> l3 = Lists.newArrayList("or", "string", "elements"); // from varargs
5.使用Apache Commons Collections
String[] str={"aaa","bbb"};
List<String> list = new ArrayList<String>();
CollectionUtils.addAll(list, str);
System.out.println(list);
6.使用Java9的List.of()方法
Integer[] array = {1, 2, 3};
List<Integer> list = List.of(array);



